
最近我沉浸在 LLM(大语言模型)的微调工作中。
在去年的 Microsoft Ignite 2024 大会上,微软发布了名为 Azure Content Understanding 的服务。该服务能以 Office 文档、图像、音频、视频等文件为基础,利用生成式 AI 等技术,将数据导入用户自定义的结构中,以便在 RAG(检索增强生成)系统等场景中轻松使用。
以往处理这类数据时,音频需要用到 Speech Service(语音服务),图像需要用到 AI Vision(人工智能视觉)等不同服务分别进行数据处理,而现在只需通过这一项服务定义好结构,就能完成所有处理流程。本次我们就将使用 Azure Content Understanding,从视频中创建便于导入搜索引擎等系统的 JSON 格式结构化数据。
Azure Content Understanding 是什么
正如文章开头所介绍的,Azure Content Understanding 能够通过单一服务从多种格式的文件中创建结构化数据。
在创建结构化数据的过程中,可实现如图所示的文件内文字提取、转录文本生成等内容提取操作。此外,通过生成式 AI 从提取的内容中生成用户定义的项目,还能将文件转换为结构化数据。
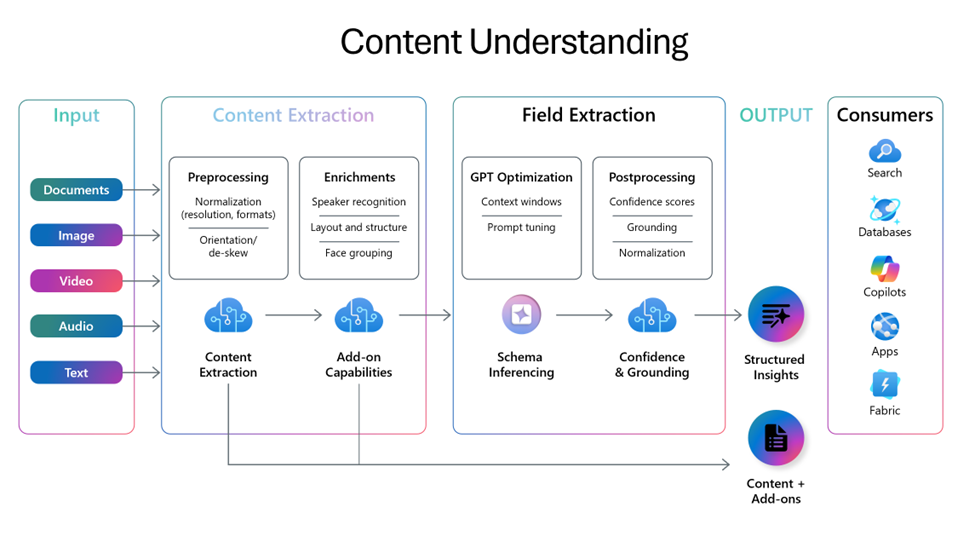
以文档转换为检索数据为例,原本需要通过 OCR(光学字符识别)提取字符串→使用 LLM 提取数据→转换为 JSON 这样的流水线式实现,而借助该功能,只需创建相应定义即可完成,非常便捷。而且单一服务就能支持多种文件类型的处理。
目前该服务处于预览阶段,暂可免费使用,价格详情将在后续公布。
使用 Azure Content Understanding 的准备工作
要使用 Azure Content Understanding,需在 West US(美国西部)、Sweden Central(瑞典中部)、Australia East(澳大利亚东部)这三个区域中的任意一个创建 Azure AI Services 资源。请注意,其他区域暂不支持该服务。
使用 Azure Content Understanding 解析视频文件
接下来,我们实际使用 Azure Content Understanding 从视频文件中提取摘要和类别信息。本次将借助以下链接提供的示例,通过 Python 来执行操作。
示例链接:github.com
具体实施步骤如下:
- 创建数据分析定义
- 创建分析器
- 使用分析器对文件进行分析
创建数据分析定义
首先,定义目标文件格式以及需要提取的数据内容。
创建如下 JSON 文件:
{
"description": "从视频中提取文件的示例",
"scenario": "videoShot",
"config": {
"returnDetails": true,
"locales": [
"ja-JP"
],
"enableFace": false
},
"fieldSchema": {
"fields": {
"summary": {
"type": "string",
"method": "generate",
"description": "概括内容的一句话"
},
"category": {
"type": "string",
"method": "classify",
"description": "视频文件的类别",
"enum": [
"IT",
"Economy",
"Nature"
]
}
}
}
}
该定义的核心要点如下:
- 因目标为视频,需在
scenario(场景)中指定videoShot locales(区域设置)中因需处理日语,仅配置ja-JP- 在
fieldSchema(字段 schema)中定义以下两个需提取的项目:summary:概括视频内容的文本category:从 IT、Economy(经济)、Nature(自然)中选择的视频类别
在fieldSchema的设置内容中,生成式 AI 会根据description(描述)的内容提取字段信息,因此description是重要的调优项。不过本次仅为简单的功能验证,故使用简洁的描述进行测试。
创建分析器
完成定义后,需创建用于读取文件并进行分析的分析器。目前仅能通过 GUI(图形用户界面)或 REST API 创建和运行分析器。但上述 GitHub 链接中提供了对 API 进行封装的工具类,本次将使用该工具类进行开发。
通过以下代码即可创建分析器:
import uuid
# 生成分析器名称
ANALYZER_TEMPLATE = "video"
ANALYZER_ID = "video-sample-" + str(uuid.uuid4())
# 创建ContentUnderstanding客户端
client = AzureContentUnderstandingClient(
endpoint=AZURE_AI_ENDPOINT,
api_version=AZURE_AI_API_VERSION,
subscription_key=AZURE_AI_SUBSCRIPTION_KEY
)
# 读取数据分析定义并创建分析器
response = client.begin_create_analyzer(ANALYZER_ID, analyzer_template_path="./content_video.json")
result = client.poll_result(response)
执行到这里,分析器就创建完成了,接下来只需执行分析操作即可。
运行分析器
接下来,我们让分析器加载视频文件并执行分析。
本次分析的目标文件是视频:www.youtube.com
该视频讲解了子网掩码的基础知识,因此预期结果是能够提取出相关内容。
执行过程非常简单,仅需以下 2 行代码即可完成:
response = client.begin_analyze(ANALYZER_ID, file_location=analyzer_sample_file_path)
result = client.poll_result(response)
获取分析结果所需的时间因文件而异,本次针对 11 分钟的视频,大约花费了 5 分钟。
分析结果
最终会得到如下所示的 JSON 数据,因完整内容过长,此处仅节选部分展示:
{
"id": "82eb4975-4232-44a1-a4e6-d018fa45469f",
"status": "Succeeded",
"result": {
"analyzerId": "video-sample-31341919-bf0d-45af-9228-7866b252a70a",
"apiVersion": "2024-12-01-preview",
"createdAt": "2025-01-28T05:32:48Z",
"warnings": [],
"contents": [
{
"markdown": "# 片段 00:00.000 => 00:03.303\n## 转录文本\n```\nWEBVTT\n\n```\n## 关键帧\n- 00:00.825 \n- 00:01.650 \n- 00:02.475 ",
"fields": {
"category": {
"type": "string",
"valueString": "IT"
},
"summary": {
"type": "string",
"valueString": "这是面向新入职年轻工程师的IT基础知识讲解视频,本次将介绍子网掩码与CIDR。"
}
},
"kind": "audioVisual",
"startTimeMs": 0,
"endTimeMs": 3303,
"width": 1280,
"height": 720,
"KeyFrameTimesMs": [
825,
1650,
2475
],
"transcriptPhrases": []
},
{
"markdown": "# 片段 00:03.303 => 01:02.106\n## 转录文本\n```\nWEBVTT\n\n00:04.680 --> 00:28.960\n<v 讲解者>接下来我们来介绍子网掩码。刚才我们讲了设置本地网络,并在其中配置和使用IP地址的内容。那么具体如何定义本地网络呢?这里我们采用将IP地址分为网络部分和主机部分的方式来考虑。\n00:29.480 --> 00:59.000\n<v 讲解者>具体怎么做呢?当有一个IP地址时,我们把其中的每个数字用比特来表示,也就是用二进制来书写。这样就会形成这样的形式,此时以某个位置为界限,前半部分称为网络部分,后半部分称为主机部分。可以说,前半部分的网络部分代表了网络本身。\n00:59.600 --> 01:27.680\n<v 讲解者>就是这样。而后面的主机部分则代表了隶属于该网络的各个设备的位置。也就是说,只要前半部分的网络部分一致,就会被视为同一个网络。关于网络的定义方式,“类”的概念从以前就一直在使用。类分为三种,即A类、B类、C类。\n```\n## 关键帧\n- 00:06.072 \n- 00:08.844 \n- 00:11.616 \n- 00:14.388 \n- 00:17.160 \n- 00:19.932 \n- 00:22.704 \n- 00:25.476 \n- 00:28.248 \n- 00:31.020 \n- 00:33.792 \n- 00:36.564 \n- 00:39.336 \n- 00:42.108 \n- 00:44.880 \n- 00:47.652 \n- 00:50.424 \n- 00:53.196 \n- 00:55.968 \n- 00:58.740 ",
"fields": {
"summary": {
"type": "string",
"valueString": "讲解者对子网掩码进行了说明,介绍了将IP地址分为网络部分和主机部分的方法,同时也提及了A类、B类、C类的网络定义方式。"
},
"category": {
"type": "string",
"valueString": "IT"
}
},
"kind": "audioVisual",
"startTimeMs": 3303,
"endTimeMs": 62106,
"width": 1280,
"height": 720,
"KeyFrameTimesMs": [
6072,
8844,
11616,
14388,
17160,
19932,
22704,
25476,
28248,
31020,
33792,
36564,
39336,
42108,
44880,
47652,
50424,
53196,
55968,
58740
],
"transcriptPhrases": [
{
"speaker": "speaker",
"startTimeMs": 4680,
"endTimeMs": 28960,
"text": "接下来我们来介绍子网掩码。刚才我们讲了设置本地网络,并在其中配置和使用IP地址的内容。那么具体如何定义本地网络呢?这里我们采用将IP地址分为网络部分和主机部分的方式来考虑。",
"confidence": 1,
"words": [],
"locale": "en-US"
},
{
"speaker": "speaker",
"startTimeMs": 29480,
"endTimeMs": 59000,
"text": "具体怎么做呢?当有一个IP地址时,我们把其中的每个数字用比特来表示,也就是用二进制来书写。这样就会形成这样的形式,此时以某个位置为界限,前半部分称为网络部分,后半部分称为主机部分。可以说,前半部分的网络部分代表了网络本身。",
"confidence": 1,
"words": [],
"locale": "en-US"
},
{
"speaker": "speaker",
"startTimeMs": 59600,
"endTimeMs": 87680,
"text": "就是这样。而后面的主机部分则代表了隶属于该网络的各个设备的位置。也就是说,只要前半部分的网络部分一致,就会被视为同一个网络。关于网络的定义方式,“类”的概念从以前就一直在使用。类分为三种,即A类、B类、C类。",
"confidence": 1,
"words": [],
"locale": "en-US"
}
]
},
推测其内部可能使用了类似 Video Indexer 的技术,能够自动将视频按章节分割,并获取每个章节的转录文本和关键帧时间。此外,自定义定义的summary(摘要)和category(类别)也能按章节获取,且内容准确无误。
只需简单定义并运行分析器,就能将视频结构化到如此详细的程度,非常便捷。同时还附带转录文本,作为检索数据也十分有效。
总结
本次我们尝试使用 Azure Content Understanding 对视频数据进行了结构化处理。
整个过程几乎无需耗费过多精力就能完成视频数据的解析,是一款非常实用的服务。虽然目前仍处于预览阶段,但该服务在 RAG 数据等场景中具有极为广泛的应用前景,未来我还会进一步探索其更多使用方法。
发表回复