
此次,我想借助 AWS 提供的开源工具 GraphRAG Toolkit,入门 GraphRAG 技术。
使用 GraphRAG Toolkit,能够以低代码方式实现基于 Amazon Neptune 和 Amazon OpenSearch Serverless 的 GraphRAG 系统。
另外,请注意,它与 2024 年 12 月起可在 Bedrock Knowledge Base 中使用的 GraphRAG 是不同的工具,请勿混淆。
1. 前言
1.1. 什么是 GraphRAG?
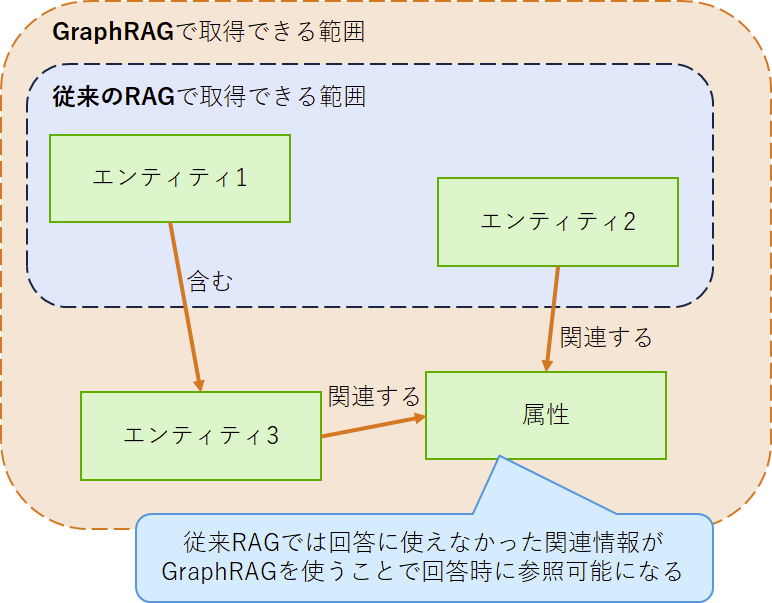
传统的 RAG(检索增强生成)采用关键词检索或向量检索来获取相关信息,而 GraphRAG 则利用知识图谱,更深入地理解检索结果的上下文,从而提取相关性更高的信息。
在传统 RAG 中,只有通过关键词检索或向量检索命中的信息才能用于回答生成;而在 GraphRAG 中,以关键词检索或向量检索得到的结果为起点,对图谱进行遍历,即便未在检索中命中但与上下文相关的信息也能被获取,并用于回答生成。
也就是说,GraphRAG 利用结构化的实体间关系,实现了精度更高的信息检索与上下文理解。
1.2. 什么是 GraphRAG Toolkit?
GraphRAG Toolkit 是 AWS 提供的开源 GraphRAG 库,提供了诸多简化基于 GraphRAG 的系统构建的功能。(参考链接:github.com)
该工具可将 Amazon Neptune Database 用作图数据库,将 Amazon OpenSearch Serverless 用作向量数据库。
通过使用此工具包,能够从非结构化数据中提取实体及其关系,将其作为知识图谱存储;并通过针对该知识图谱查询用户问题,构建可提供相关性更高信息的应用程序。本次我们将使用该工具包来尝试 GraphRAG 技术。
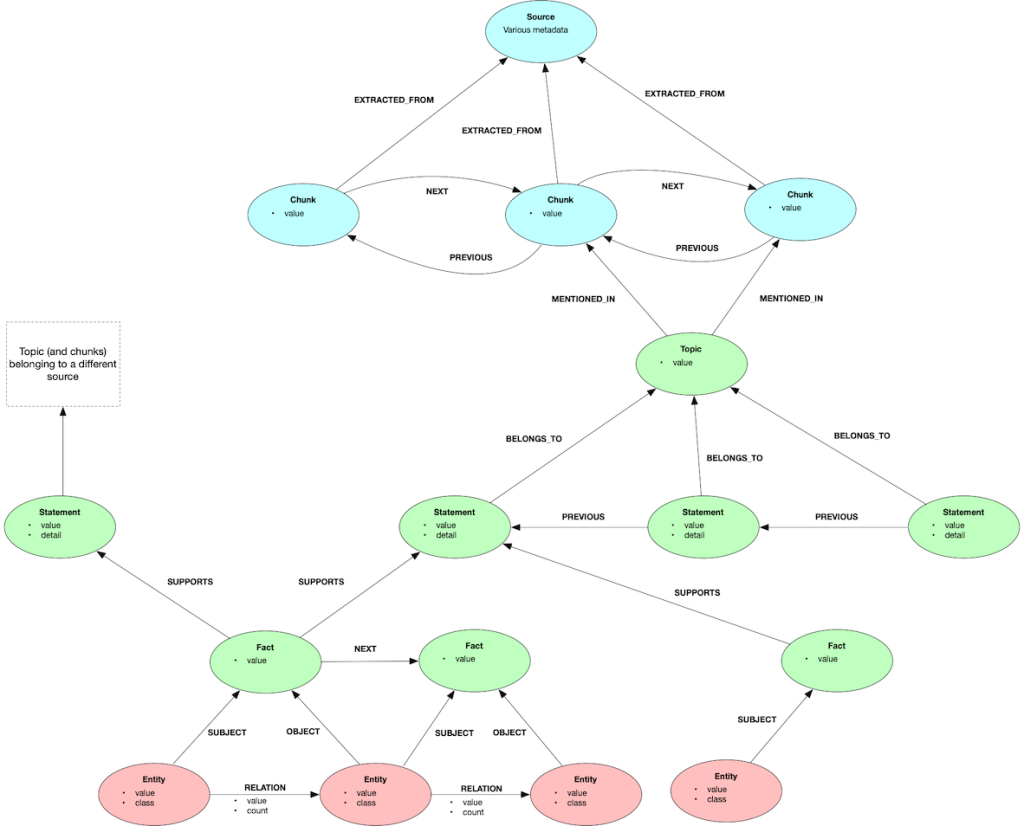
GraphRAG Toolkit 中知识图谱的基本结构
知识图谱是一种将数据构建为实体(实际存在的事物)及其关系(关联性)的结构化数据模型,用于表达数据间的语义关联。
通过将信息整理为 “实体” 与 “关系” 的网络,能够实现考虑关联性的检索以及逻辑性的推理。
在 GraphRAG Toolkit 中,知识图谱通过以下术语和结构构建。(自上而下,概念从抽象宏观逐渐过渡到具体微观。)
| 序号 | 项目 | 概述 | 示例 |
|---|---|---|---|
| 1 | 文档(Source) | 表示原始文档的属性 | https://docs.aws.amazon.com/neptune/latest/userguide/intro.html |
| 2 | 片段(Chunk) | 文档分割后的小单位 | Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. The core of Neptune is… |
| 3 | 主题(Topic) | 片段中记载的核心主题 | Amazon Neptune |
| 4 | 语句(Statement) | 片段中书写的句子或语句 | The core of Neptune is a purpose-built, high-performance graph database engine. |
| 5 | 事实(Fact) | 从语句中提炼出的事实 | Amazon Neptune HAS high-performance |
| 6 | 实体 | 事实的主语、宾语,对应现实世界的 “事物” 或 “概念” | Amazon Neptune |
1.3. 什么是 Amazon Neptune?
Amazon Neptune 是 AWS 提供的全托管型图数据库服务,能够高效管理和操作数据间的关系。
Neptune 支持多种图模型,可实现灵活的数据操作。它不仅可用于构建知识图谱,还在社交网络分析、推荐系统等多种场景中得到应用。
此外,其一大优势在于能够控制成本 —— 可在不使用的时段 “停止” 服务,在开发环境中还能选用 T3 实例等相对经济的实例类型。
2. 构建环境
本次将通过 GraphRAG Toolkit 提供的 CloudFormation 模板来搭建环境。
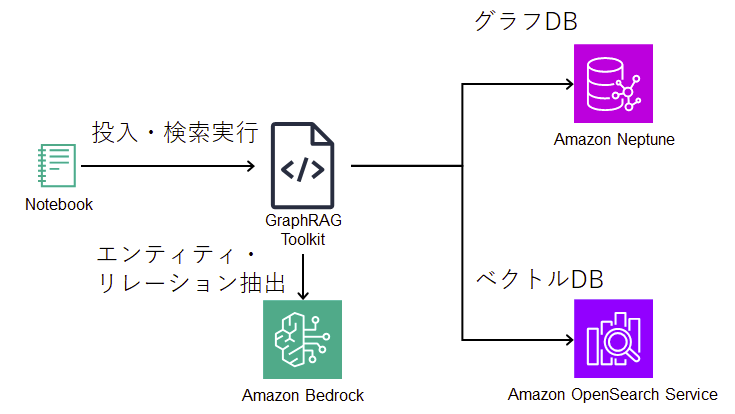
| 序号 | 项目 | 概述 |
|---|---|---|
| 1 | Amazon Neptune | 存储知识图谱并提供检索功能 |
| 2 | Amazon OpenSearch Service | 配合图检索使用,用于向量检索 |
| 3 | Amazon Bedrock | 从片段中提取主题、语句、事实、实体;生成用于存入向量数据库的向量・提取模型:Claude-3-Sonnet・向量化模型:Titan Text Embedding V2 |
| 4 | Notebook(笔记本) | 操作 GraphRAG Toolkit,执行文档导入与检索操作 |
3. 导入数据
使用上述 CloudFormation 模板搭建环境后,系统会提供多个示例笔记本。数据导入可选择以下两种笔记本之一:
01-Combined-Extract-and-Build.ipynb:一站式完成从文档中提取实体等信息及构建图谱的操作02-Separate-Extract-and-Build.ipynb:将实体等信息的提取与图谱构建拆分为独立步骤执行
文档导入按以下流程进行:
- 文档分割(Chunking):将文档拆分为细小的单元
- 提取命题(Proposition):将片段传入大语言模型(LLM),提取命题命题是为提取构建知识图谱所需的 6 类要素而生成的预处理结果,会对原始文档进行清洗,例如将复杂句子拆分为简单易懂的句子、展开代词和缩写等。
- 提取核心要素:将命题传入 LLM,提取主题、语句、事实、实体
- 构建并导入知识图谱:根据提取的实体等信息构建知识图谱,存入图数据库
- 向量化并导入向量数据库:将语句传入 LLM 进行嵌入(Embedding)处理,生成向量后存入向量数据库
使用 GraphRAG Toolkit 时,只需调用 extract 方法,即可一键执行上述所有流程,上手非常简单。
3.1. 确认待导入的数据
本次将使用 02-Separate-Extract-and-Build.ipynb 笔记本,确认提取模型如何处理原始文档,使其转化为可导入图数据库的格式。
执行笔记本中的 “Extract(提取)” 阶段后,LLM 会解析文档,提取实体、属性以及各类关系。提取结果将保存至 extracted/ 目录下。
通过修改配置,也可将提取结果保存至 S3。这样一来,可将已处理的数据存储在 S3 中,当新增数据需要重新构建知识图谱、或需在其他数据库中构建相同知识图谱时,无需重复执行提取操作,既能规避 LLM 的调用限制,又能节省成本。
实际输出到 extracted/ 目录的 JSON 文件内容如下(因篇幅有限,已大幅省略)。从中可以看出,前文所述的命题、主题、语句、事实、实体均以嵌套形式存储。
{
"id_": "aws:xxxx",
"metadata": {
"url": "https://docs.aws.amazon.com/neptune-analytics/latest/userguide/what-is-neptune-analytics.html",
"aws::graph::propositions": [
// 命题
"Neptune Analytics is a memory-optimized graph database engine for analytics",
"Neptune Analytics allows getting insights and finding trends by processing large amounts of graph data in seconds"
],
"aws::graph::topics": {
"topics": [
{
// 主题
"value": "Neptune Analytics",
"entities": [
{
// 实体
"value": "Neptune Analytics",
"classification": "Software"
}
],
"statements": [
{
// 语句
"value": "Neptune Analytics is a memory-optimized graph database engine for analytics",
"facts": [
// 事实
{
"subject": {
"value": "Neptune Analytics",
"classification": "Software"
},
"predicate": {
"value": "OPTIMIZED FOR"
},
"complement": "memory"
}
]
}
]
}
]
}
}
}
此外,对于中文文档,它也能很好地完成信息提取。
{
"id_": "aws:xxxx",
"metadata": {
"aws::graph::propositions": [
// 命题
"知识表示的方法",
"知识图谱将数据表现为实体与关系的网络",
"知识图谱是一种易于捕捉信息语义的强大方法"
],
"aws::graph::topics": {
"topics": [
{
// 主题
"value": "Knowledge Representation",
"entities": [
{
// 实体
"value": "知识图谱(知识图谱)",
"classification": "Concept(概念)"
}
],
"statements": [
{
// 语句
"value": "知识图谱将数据表现为实体与关系的网络",
"facts": [
// 事实
{
"subject": {
"value": "知识图谱(知识图谱)",
"classification": "Concept(概念)"
},
"predicate": {
"value": "REPRESENTS(表示)"
},
"object": {
"value": "数据(数据)",
"classification": "Concept(概念)"
}
}
]
}
]
}
]
}
}
}
3.2. 确认已导入的数据
通过 CloudFormation 部署 Notebook 时,图探索器(Graph Explorer)会同时完成部署。打开该图探索器,即可直观查看已构建的知识图谱。
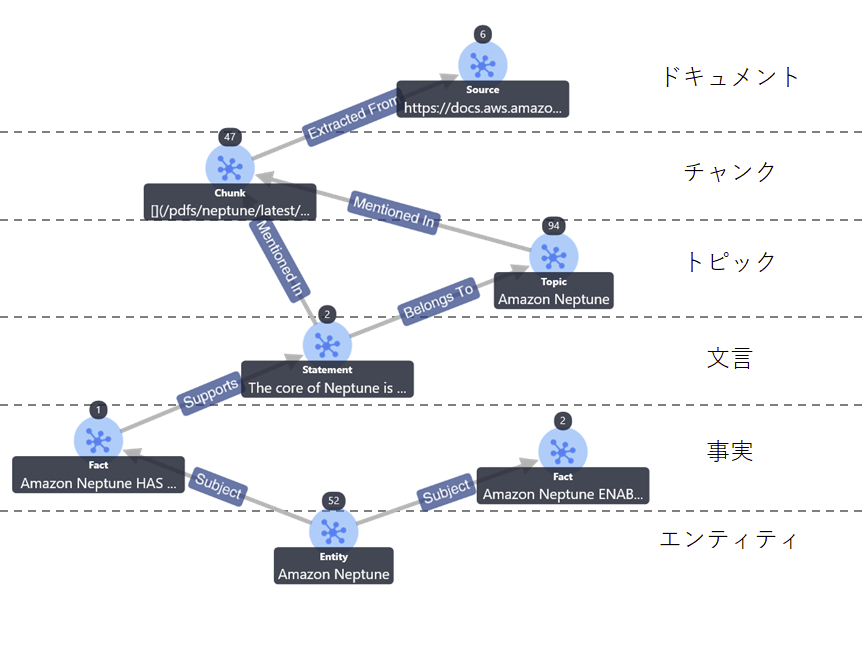
下图展示了使用 GraphRAG Toolkit 导入 Amazon Neptune 文档后构建的知识图谱的部分内容。
如前文所述,可以看到知识图谱分为文档、片段、主题、语句、事实、实体等层级,且各层级之间的关系均有明确标注。
4. 检索
在 GraphRAG 中,首先通过向量检索找到作为起点的节点,随后遍历知识图谱,最终返回检索结果。
GraphRAG Toolkit 主要提供两种检索方法,具体如下表所示:
| 序号 | 检索方法 | 优点 | 缺点 | 用途 |
|---|---|---|---|---|
| 1 | TraversalBasedRetriever | ・处理轻量化・结果可重复性高・对未知词汇及专有名词的适配性强 | ・灵活性较低・检索精度偏低 | 按类别整理的 FAQ 等场景 |
| 2 | SemanticGuidedRetriever | ・可探索符合问题意图的信息・能考虑复杂关联性・可确保检索结果的多样性 | ・计算成本高,处理负载重 | 需要灵活、高级的信息检索场景(如匹配问题意图、需多样化信息等) |
4.1. TraversalBasedRetriever(基于遍历的检索器)
TraversalBasedRetriever 是通过按顺序遍历图谱结构来扩展信息的检索方法。由于它会按固定顺序遍历知识图谱,因此处理过程较为轻量化。
TraversalBasedRetriever 包含两种具体实现方式,可单独使用其中一种,也可组合使用两种。默认设置下,返回的是两种方式组合后的结果。
1. EntityBasedSearch(基于实体的检索)
从查询字符串中提取关键词,在图谱中查找匹配的实体(自下而上,Bottom up)。找到匹配的实体后,从该实体出发,向事实、命题、主题等更宏观的概念层级遍历,从而完成检索。
其特点是,即便面对未知词汇或专有名词,也能依据预先构建的知识图谱收集相关信息。由于检索从实体出发,往往能广泛获取与该实体相关的信息。
2. ChunkBasedSearch(基于片段的检索)
利用查询与片段间的向量相似度进行检索(自上而下,Top down)。从检索命中的片段出发,向主题、命题、事实等更微观的概念层级遍历,从而完成检索。
由于检索从与查询语义相近的片段开始,往往能精准获取关联性更强的信息。
4.2. SemanticGuidedRetriever(基于语义引导的检索器)
SemanticGuidedRetriever 对语句(Statement)进行向量化处理后执行检索。针对通过向量检索获取的语句,采用波束搜索(Beam Search)与路径解析技术,从邻近节点开始探索,筛选出关联性强的信息。
此外,该检索器还集成了多种为回答生成筛选所需信息的机制,例如:通过重排序(Rerank)筛选符合问题意图的检索结果;通过多样性过滤器确保回答信息不仅局限于相似内容,而是具备多样性。
通过结合向量检索与图谱检索的混合模式,SemanticGuidedRetriever 既能保持较高的信息关联性,又能返回范围更广的检索结果,但相应地会增加处理负载。
4.3. 确认检索结果
可使用 GraphRAG Toolkit 中包含的 04-Querying.ipynb 笔记本,测试上述两种检索方法。
我们针对每个检索器提出了 “Neptune Database 与 Neptune Analytics 有什么区别?” 的问题,并确认了大语言模型(LLM)的回答及回答所使用的文档。
TraversalBasedRetriever
Neptune Database 与 Neptune Analytics 呈互补关系。
Neptune Database 是托管型图数据库服务,提供数据的持久化存储、备份、复制等功能。[https://docs.aws.amazon.com/neptune/latest/userguide/intro.html]
而 Neptune Analytics 是用于高速分析大规模图数据的内存引擎,可从 Neptune Database 或 S3 读取图数据,通过执行预构建的图算法或自定义查询进行分析。
[https://docs.aws.amazon.com/neptune-analytics/latest/userguide/what-is-neptune-analytics.html]
也就是说,Neptune Database 负责图数据的持久化存储与管理,Neptune Analytics 则是实现该数据高速分析处理的服务。通过将数据存储与分析分离,可使两者各自实现专注于自身功能的性能优化。[https://docs.aws.amazon.com/neptune-analytics/latest/userguide/neptune-analytics-features.html]
■ 文档
[
{
"source": "https://docs.aws.amazon.com/neptune-analytics/latest/userguide/what-is-neptune-analytics.html",
"topic": "Neptune Analytics",
"statements": [
"Neptune Analytics can load data from a Neptune Database graph",
"Neptune Analytics complements Amazon Neptune Database, a popular managed graph database",
"Neptune Analytics can load data from a Neptune Database snapshot",
"The Neptune Analytics vs Neptune Database page explains when to use Neptune Analytics and when to use Neptune Database",
"Neptune Analytics can load graph data stored in Amazon S3"
]
},
{
"source": "https://docs.aws.amazon.com/neptune/latest/userguide/intro.html",
"topic": "Amazon Neptune",
"statements": [
"Neptune Analytics is an analytics database engine.",
"Neptune Analytics complements Neptune database.",
"The Neptune database has continuous backup to Amazon S3",
"Amazon Neptune automatically detects database crashes and restarts",
"Amazon Neptune increases database performance and availability"
]
}
]
4.3.1. SemanticGuidedRetriever(基于语义引导的检索器)
Neptune Database 与 Neptune Analytics 是不同的产品,主要区别如下:
Neptune Database 是托管型图数据库服务,可实现数据的持久化存储与低延迟的查询执行。[https://docs.aws.amazon.com/neptune/latest/userguide/intro.html]
而 Neptune Analytics 是用于在内存中分析图数据的引擎,可将大规模图数据集加载到内存中,高速执行预先准备的高级分析算法及自定义 Cypher 查询。
[https://docs.aws.amazon.com/neptune-analytics/latest/userguide/what-is-neptune-analytics.html]
Neptune Analytics 适用于数据分析、数据科学及探索性工作负载。
也就是说,Neptune Database 的主要目的是数据的持久化存储与低延迟查询执行,而 Neptune Analytics 的主要目的是在内存中实现大规模图数据的高速分析。此外,Neptune Analytics 也可从 Neptune Database 读取数据并进行分析。[https://docs.aws.amazon.com/neptune-analytics/latest/userguide/what-is-neptune-analytics.html]
■ 文档
<sources>
<source_1>
<source_1_metadata>
<url>https://docs.aws.amazon.com/neptune-analytics/latest/userguide/what-is-neptune-analytics.html</url>
</source_1_metadata>
<statement_1.1>Neptune Analytics is a memory-optimized graph database engine for analytics</statement_1.1>
<statement_1.2>Neptune Analytics is a memory-optimized graph database engine for analytics</statement_1.2>
<statement_1.3>Neptune Analytics can load data from a Neptune Database graph</statement_1.3>
<statement_1.4>Neptune Analytics can load data from a Neptune Database snapshot</statement_1.4>
<statement_1.5>Neptune Analytics is an ideal choice for data-science workloads that require fast iteration for data, analytical and algorithmic processing, or vector search on graph data</statement_1.5>
</source_1>
<source_2>
<source_2_metadata>
<url>https://docs.aws.amazon.com/neptune/latest/userguide/intro.html</url>
</source_2_metadata>
<statement_2.1>Neptune Analytics is an analytics database engine.</statement_2.1>
<statement_2.2>Neptune Analytics is a solution for quickly analyzing existing graph databases.</statement_2.2>
<statement_2.3>Neptune Analytics is a solution for quickly analyzing graph datasets stored in a data lake.</statement_2.3>
<statement_2.4>Amazon Neptune is a fully managed graph database service</statement_2.4>
<statement_2.5>Amazon Neptune is a fully managed graph database service</statement_2.5>
</source_2>
</sources>
直观来看,使用 SemanticGuidedRetriever 得到的回答似乎更准确,但不同检索方法在检索精度上的差异等问题,我们将留作后续的验证课题。
此外,TraversalBasedRetriever 与 SemanticGuidedRetriever 返回结果中包含的文档格式存在差异,不过据了解,该问题将在后续更新中实现统一。
总结
本次我们通过 GraphRAG Toolkit,了解了 GraphRAG 处理数据的具体流程。通过实际运行并确认内部机制,我认为已经理解了 GraphRAG 的特性。
同时,我们也发现,借助 GraphRAG Toolkit 能够非常轻松地构建 GraphRAG 系统。该工具包封装了将数据导入图数据库前的繁琐处理流程,这一点十分令人满意。
发表回复