
本文将介绍在 AWS 上使用 Elasticsearch(Elastic Cloud)的要点。在本文中,将统一把 Elastic Cloud(Elasticsearch Service)简称为 “Elastic Cloud”。
1. 监控(Monitoring)设置(Metric/Logs)
关于Monitoring功能
通过使用Monitoring功能,可一目了然地掌握集群状态;即便发生故障,也能从资源和日志两方面快速排查问题。
在 Elastic Cloud 中启用Monitoring功能
Monitoring功能默认处于未启用状态,需按以下步骤启用:
(1) 访问 Elastic Cloud 的Deployment页面,点击菜单中的 “Logs and metrics”。
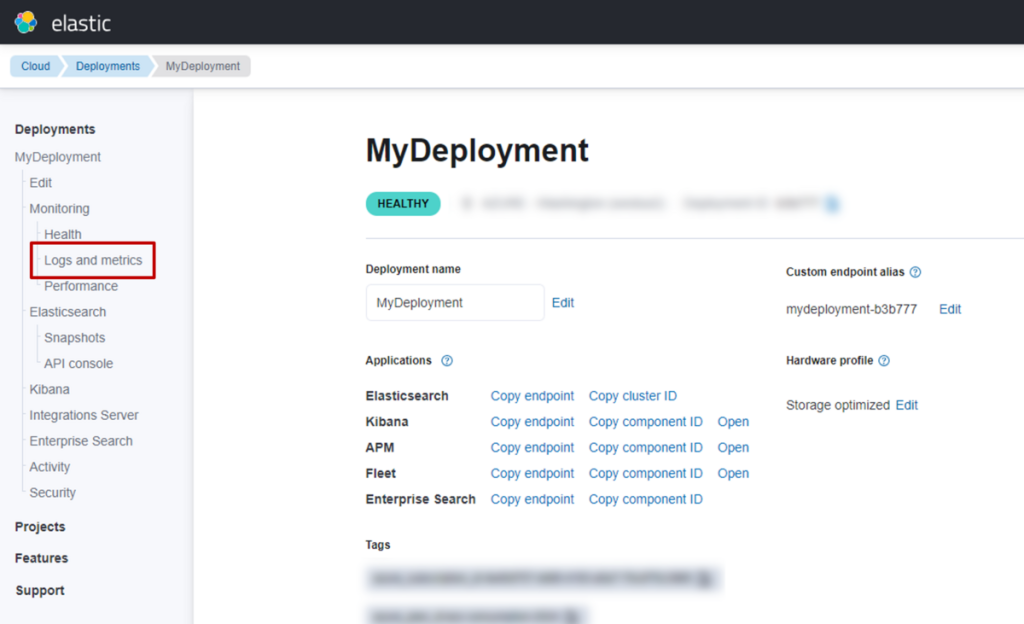
(2) 点击 “Ship to a deployment”下方的 “Enable”。
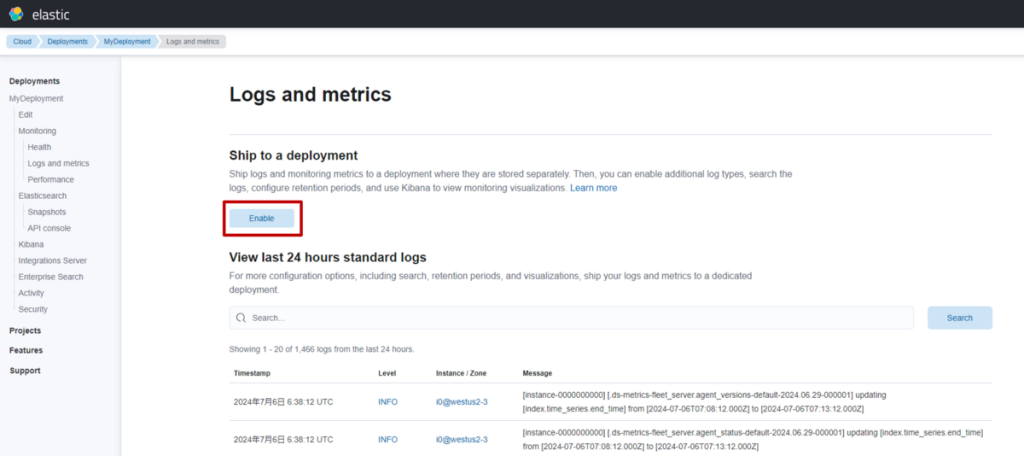
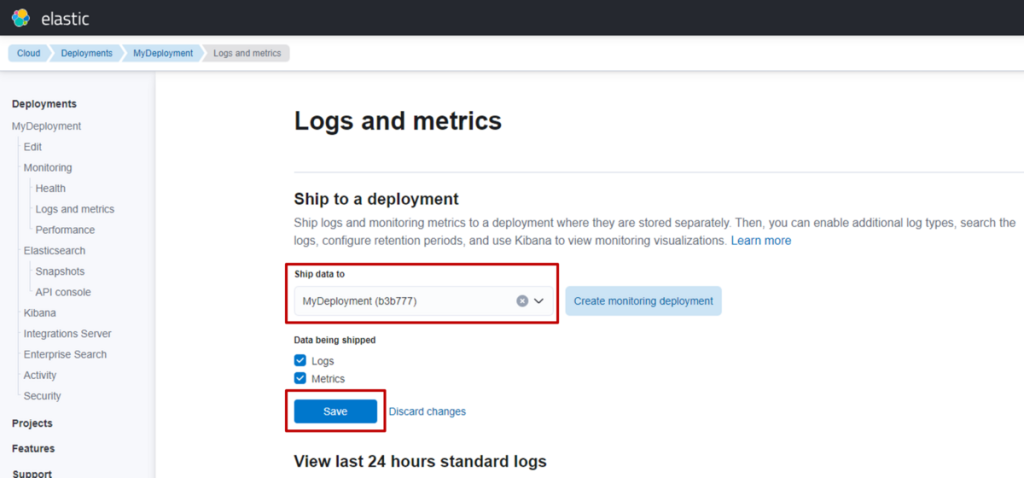
(3) 选择已搭建的部署,点击 “Save”,Monitoring功能即启用。
查看指标(Metric)
通过指标可查看 Elastic Stack 各组件的服务器资源使用情况:
(1) 在 Kibana 页面左侧菜单中,点击 “Stack Monitoring”
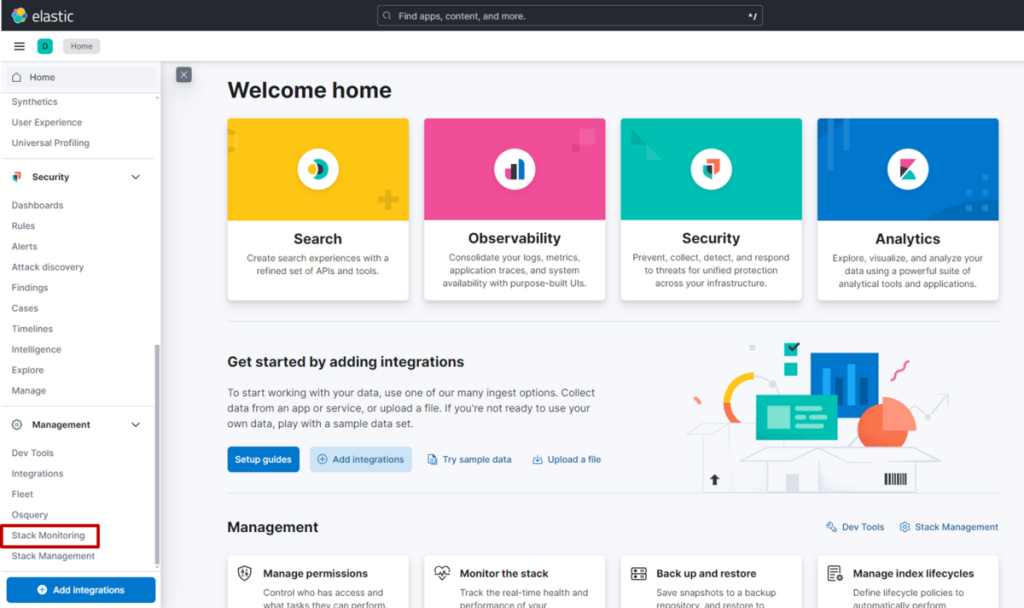
(2) 点击 Elasticsearch 的 “Overview”。在概览页面中,可实时查看 Elasticsearch 整体的搜索性能与索引性能。
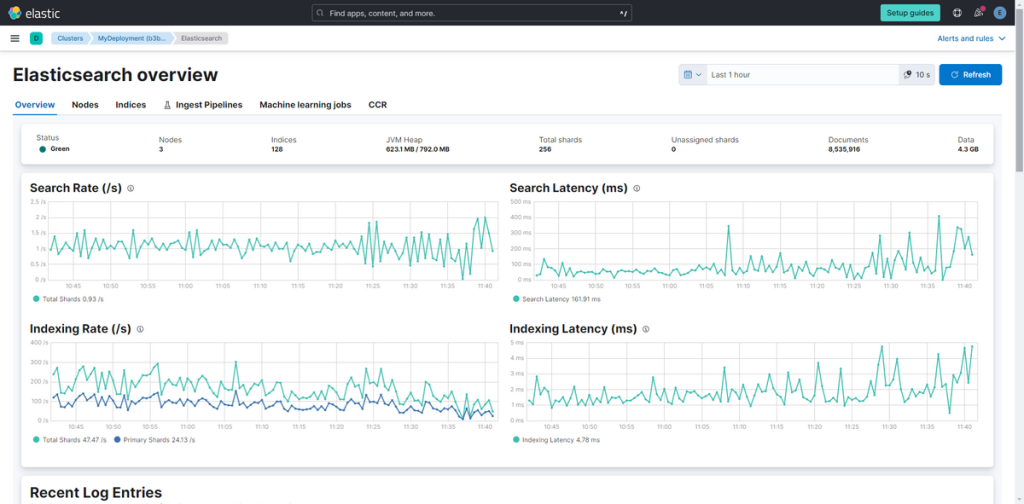
(3) 在 Elasticsearch 的 “Nodes”中,选择并点击一个实例。
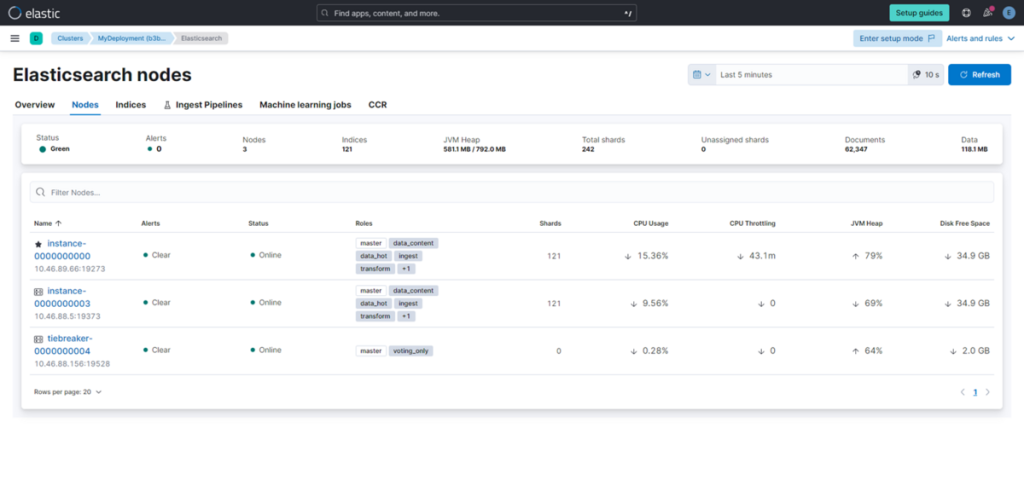
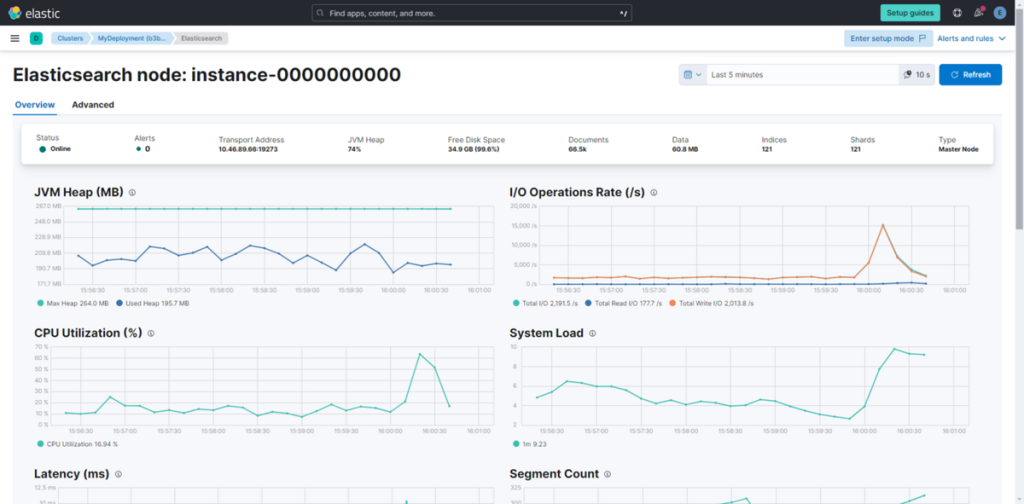
此时可实时查看每台服务器的资源状态。
查看日志(Logs)
通过日志可实时查看、筛选日志并进行问题排查:
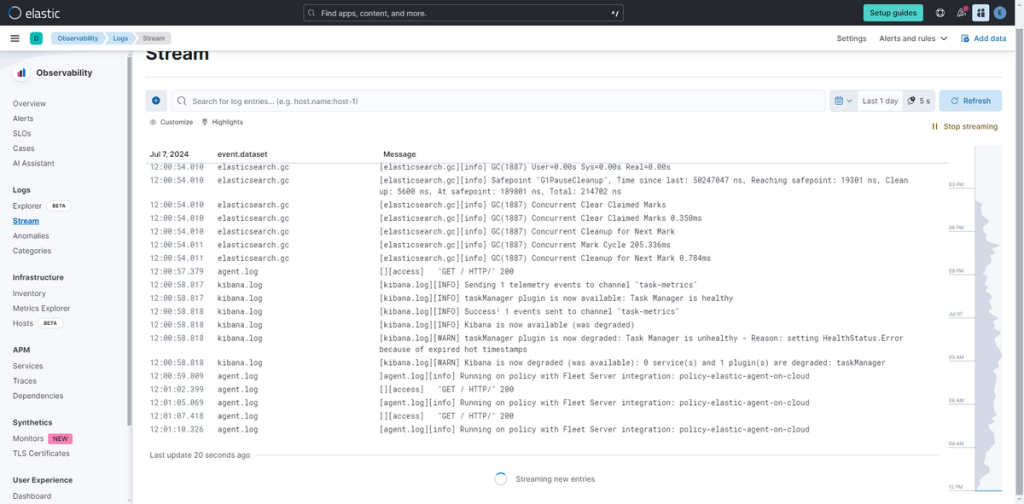
(1) 在 Kibana 页面左侧菜单中,点击 “Logs”。
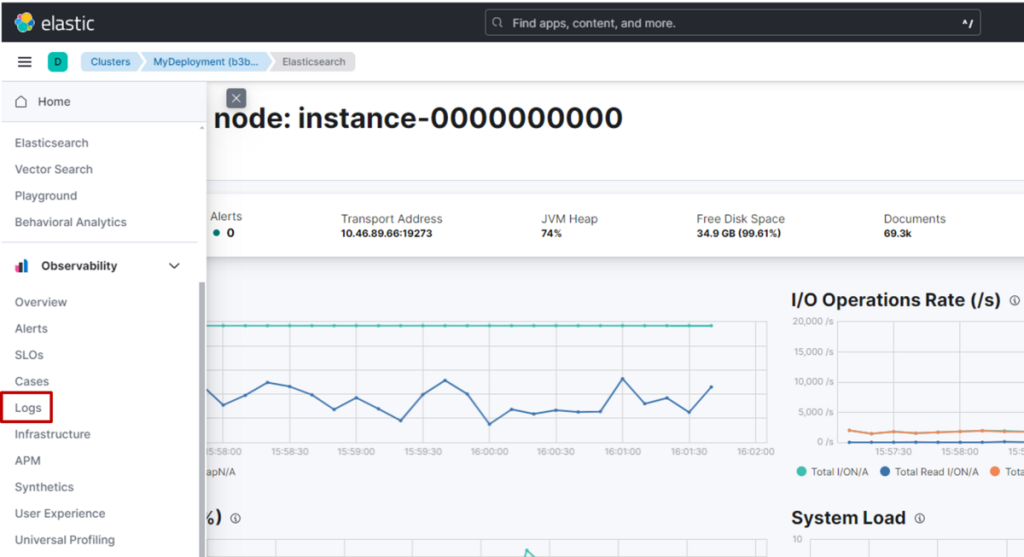
在Stream页面中,会实时显示导入 Elasticsearch 的各类日志。
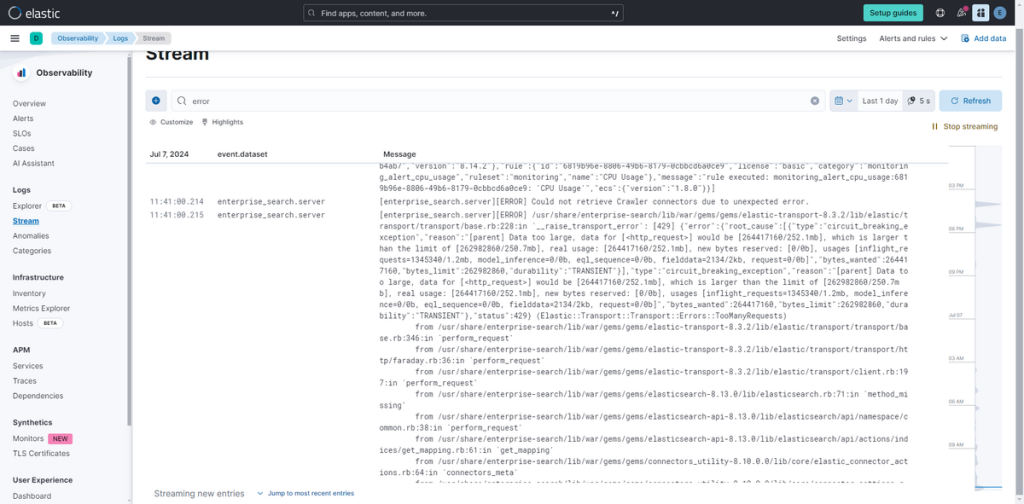
(2) 在页面上方的搜索框中输入 “error”,执行日志筛选。
可以一边筛选日志,一边开展问题排查。
修改指标的保留期限
指标的默认保留期限为 3 天。由于不同需求下的保留期限可能不同,建议根据实际情况修改设置:
(1) 在 Kibana 页面左侧菜单中,点击 “Stack Management”
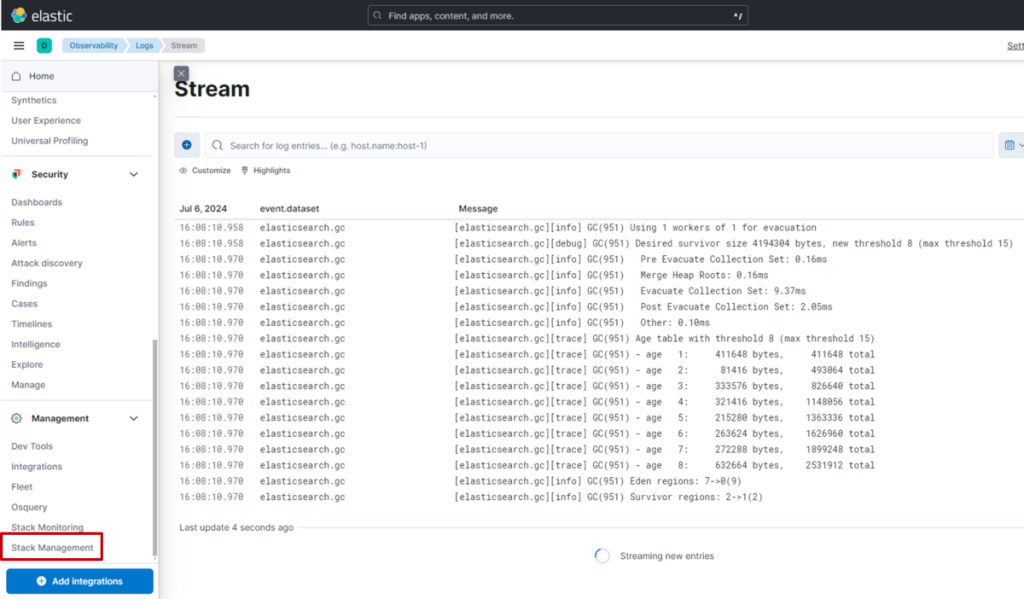
(2) 点击 “Index Lifecycle Policies”。
(3) 在搜索框中输入 “.monitoring”,点击显示结果中的 “.monitoring-8-ilm-policy”。
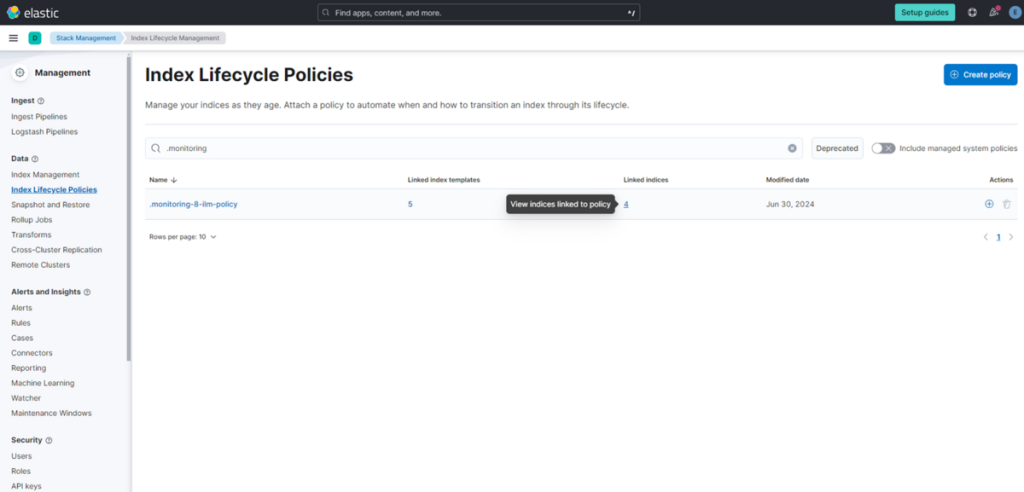
Elasticsearch 会将索引按 “阶段(Phase)” 进行管理,各阶段的过渡条件通过 ILM(索引生命周期管理,Index Lifecycle Management)定义。
详情可参考以下链接:ILM: Manage the index lifecycle | Elasticsearch Guide [8.14] | Elastic
修改前的设置如下表所示:
| 阶段(Phase) | 设定值 |
|---|---|
| Hot 阶段 | 索引创建后满 3 天,或主分片(Primary Shard)大小达到 50GB 以上时,对索引执行 Rollover |
| Warm 阶段 | 执行强制合并(Forcemerge),将分片的段(Segment)数量合并为 1 |
| Delete 阶段 | 索引执行 Rollover 后满 3 天,将其删除 |
简单来说,Hot 阶段中定义的 “Rollover” 是指当满足特定条件时,自动创建新索引的功能。
详情可参考以下链接:Rollover | Elasticsearch Guide [8.14] | Elastic
(4) 将 Delete 阶段的保留时间从 “3 天” 修改为 “31 天”,点击 “Save Policy”。
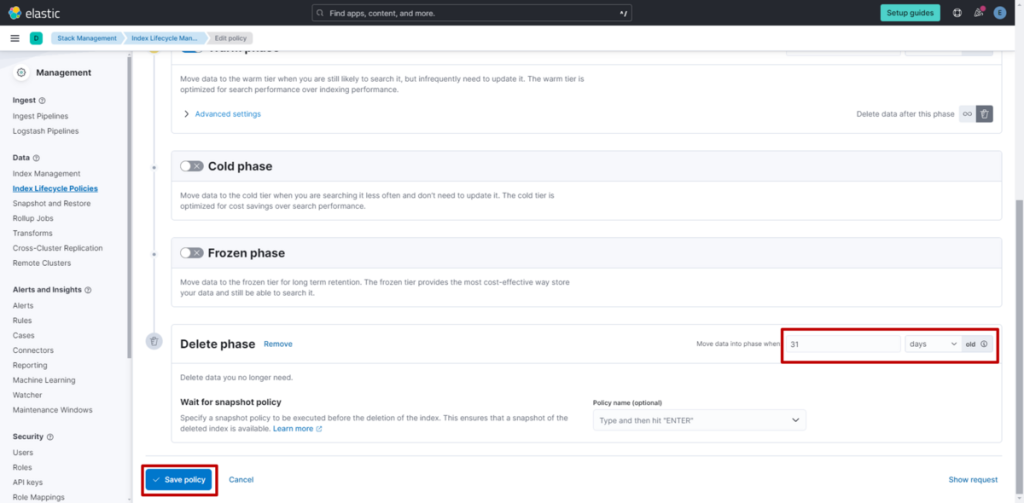
通过上述步骤,已成功将设置修改为:索引执行 Rollover 后满 31 天自动删除。
2. Snapshot设置
关于Snapshot设置
在 Elastic Cloud 中,默认设置为每 30 分钟创建一次Snapshot。下面将介绍如何确认并修改该设置:
(1) 在 Kibana 页面左侧菜单中,点击 “Stack Management
(2) 点击 “Snapshot and Restore”
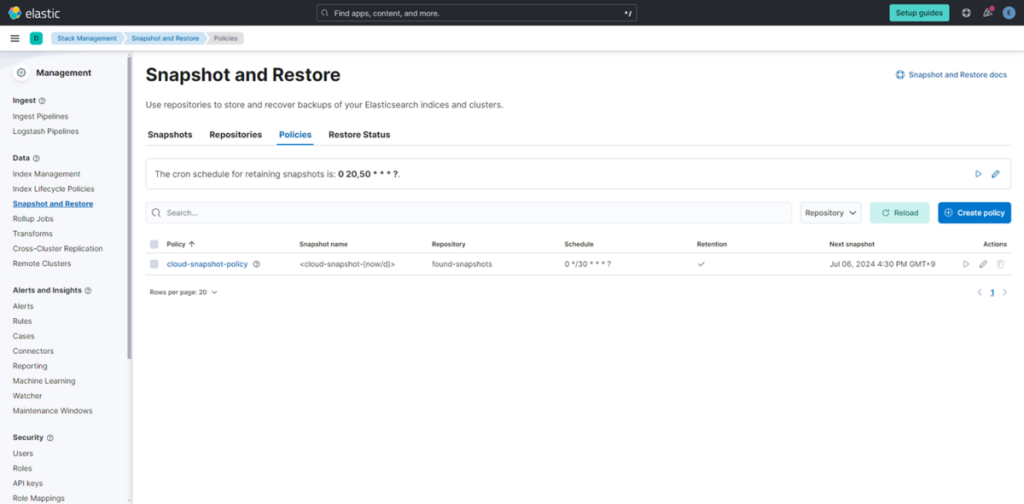
(3) 点击 “Policies” 标签页,点击 “cloud-snapshot-policy” 右侧的 “Edit” 按钮。
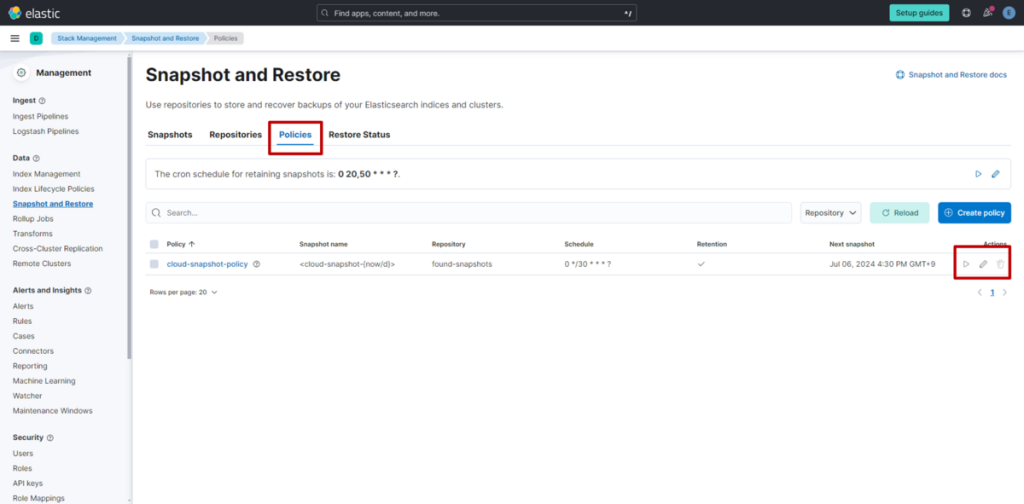
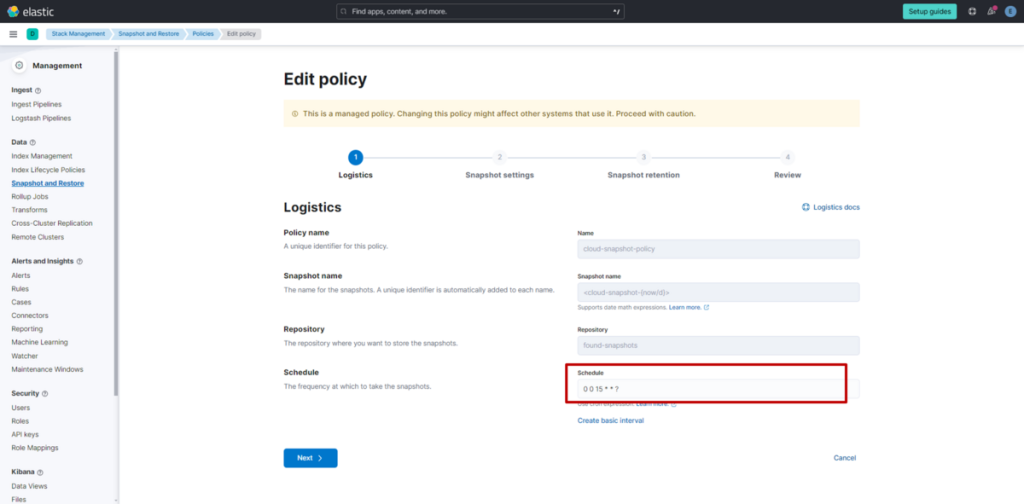
(4) 修改 “Schedule” 的设置值
时间设置支持使用 Cron 表达式,请注意时区为 UTC(世界协调时间)。
详情可参考以下文档:API conventions | Elasticsearch Guide [8.14] | Elastic
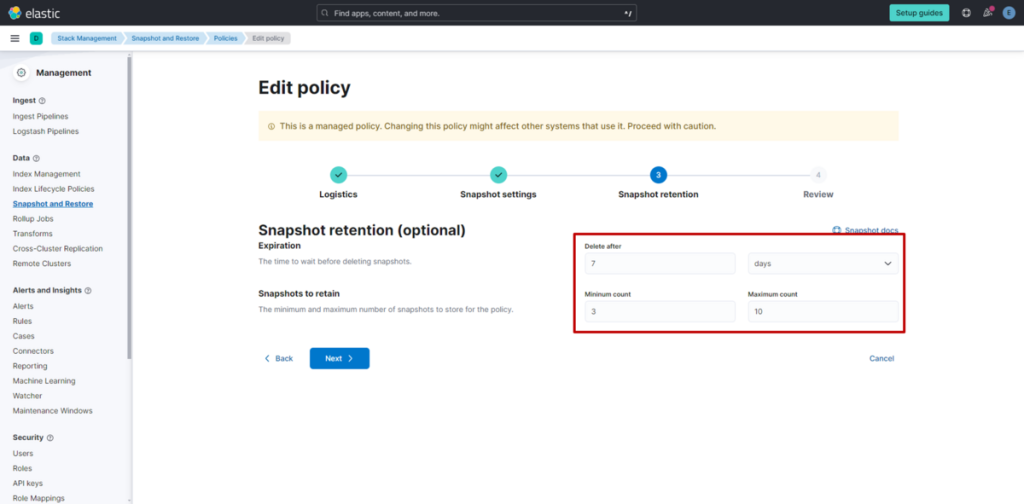
(5) 根据需求修改 “Expiration”“Snapshots to retain” 的设置值。
(6) 点击 “Save policy”
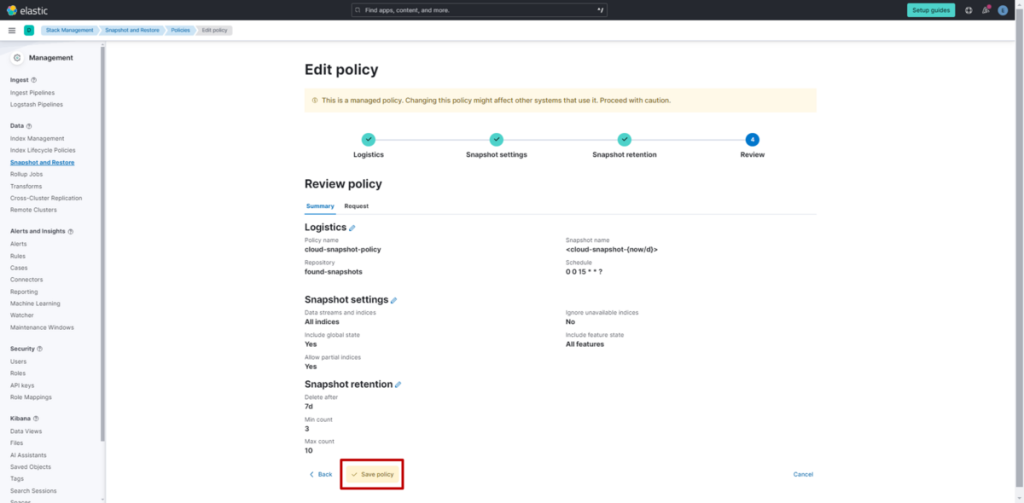
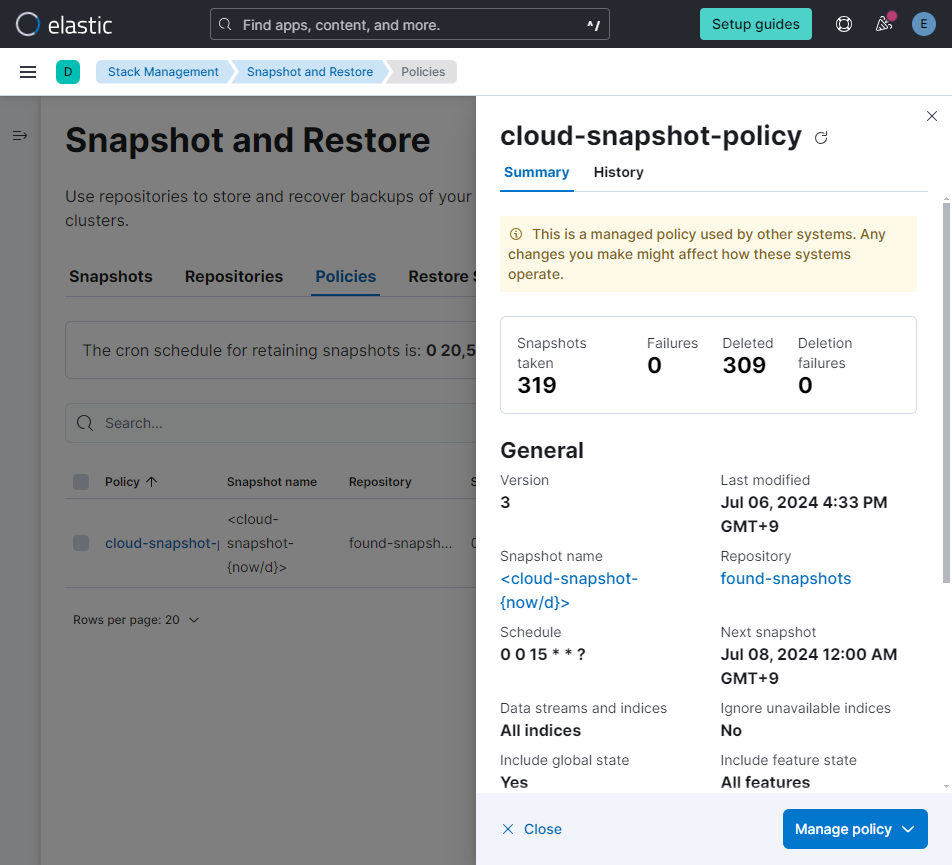
(7) 点击 “cloud-snapshot-policy”,查看 “Summary”。修改后,snapshot将按设置在每天 0 点创建。
3. Alert设置
关于 Elastic Cloud 的Alert功能
在 Elastic Cloud 中,可通过 “Alert” 功能实现监控与通知。默认情况下,系统提供了多个可配置的监控项,便于快速完成Alert设置。下面将介绍如何创建默认规则并使用Alert功能:
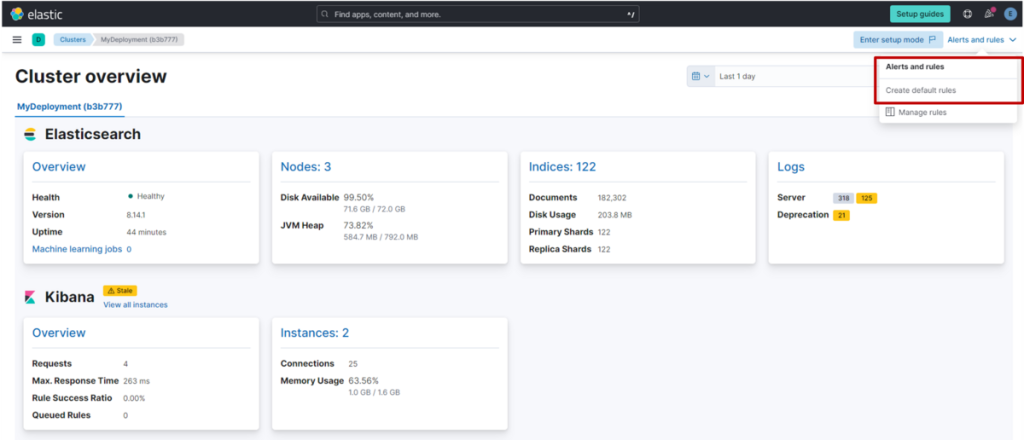
(1) 从左侧菜单点击 “Stack Monitoring”,在监控页面右上角选择 “alerts and rules”,点击 “Create default rules”。
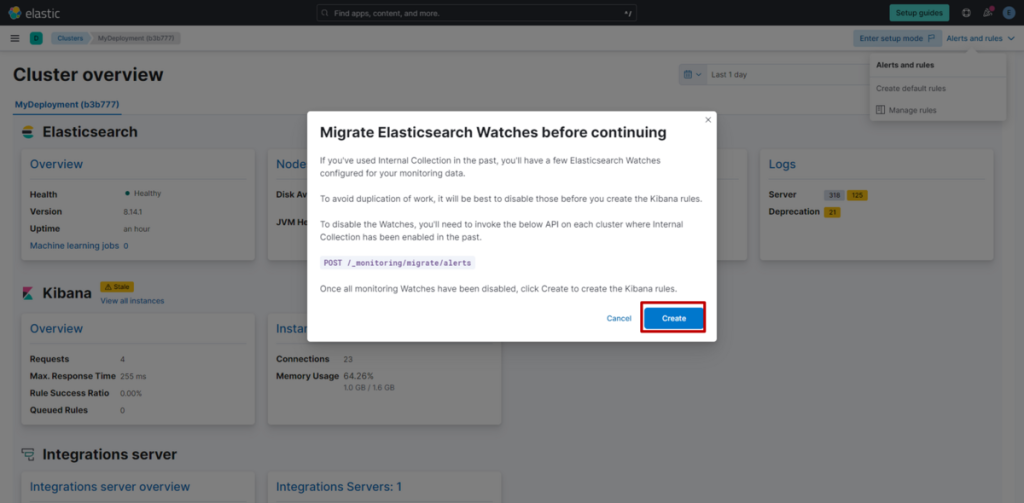
(2) 点击 “Create”。至此,Alert设置完成。最后我们来确认已创建的规则列表:
(3) 点击 “Stack Management”,选择 “Alerts”,然后点击页面右上角的 “Manage rules”。
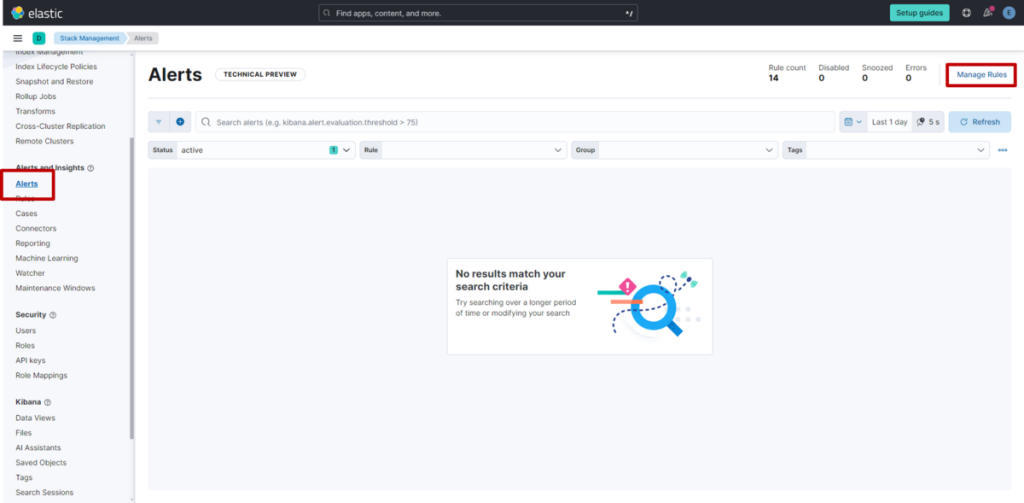
此时会显示已创建的规则列表。通过编辑规则,可修改告警条件或配置通知方式。
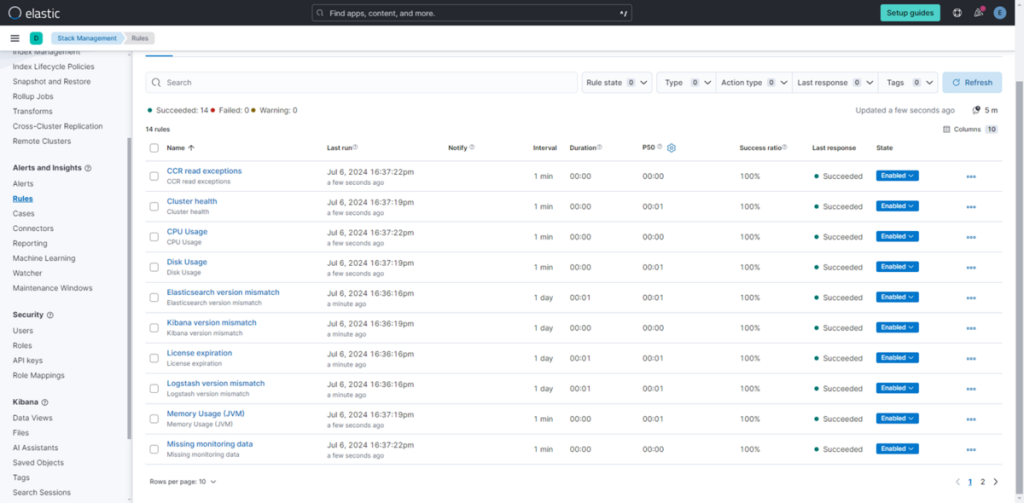
例如,“CPU Usage” 规则的默认配置为:当 CPU 使用率 5 分钟平均值超过 85% 时,触发告警并发送通知。
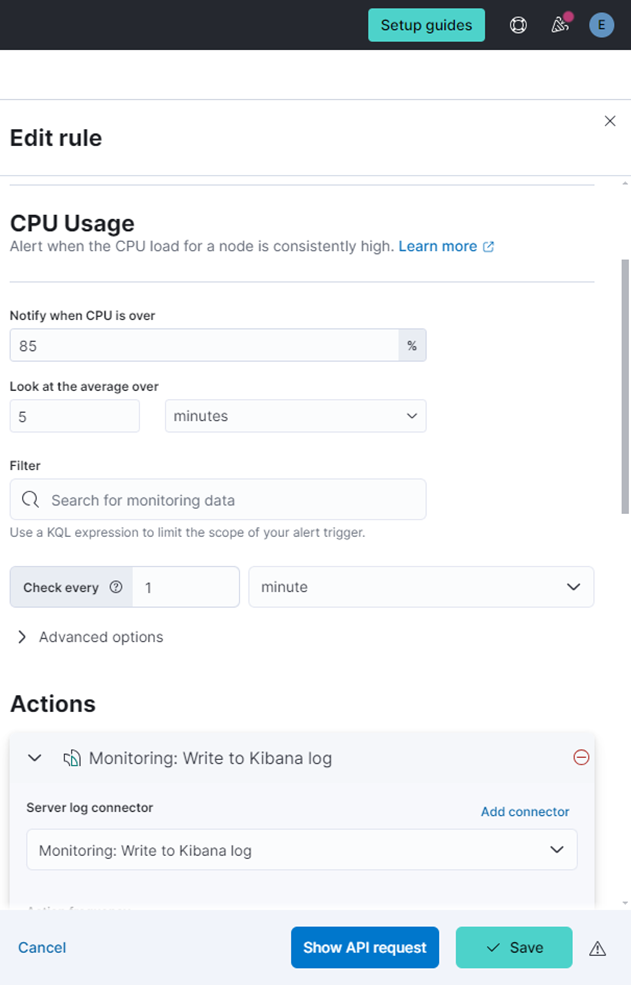
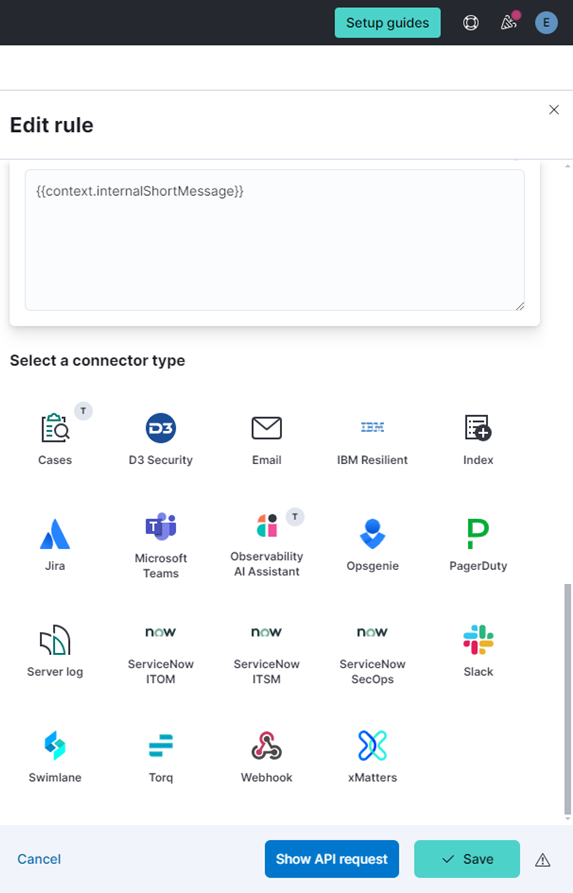
此外,通知的默认接收方式为 “输出到 Kibana 日志”,但系统也支持配置邮件、Slack 等多种连接器(Connector)作为通知渠道。
总结
在实际运维过程中,除了上述 内容外,可能还需要以下操作:
- 版本升级应对
- 审计日志
因此,在下次的文章中,我会对上述内容进行讲解。
发表回复