
在 RAG(检索增强生成:Retrieval-Augmented Generation)为用户提供准确信息的过程中,检索精度尤为关键。
而提升检索精度的方法之一便是 “重排序(Rerank)”。
通过执行重排序操作,将检索得到的结果按相关度重新排序,能更轻松地针对用户所需信息给出回答。
如今,Amazon Bedrock 已新增支持重排序的模型,且可与 Bedrock Knowledge Base 搭配使用。
以往,实现这一功能需要自行托管模型等,颇为繁琐;而现在,只需在向 Knowledge Base 发起的检索请求中添加相关设置,即可一并执行检索与重排序操作,且仅能获取重排序后的结果。
本次我们将实际使用重排序模型,验证检索结果会发生怎样的变化。
1. 前言
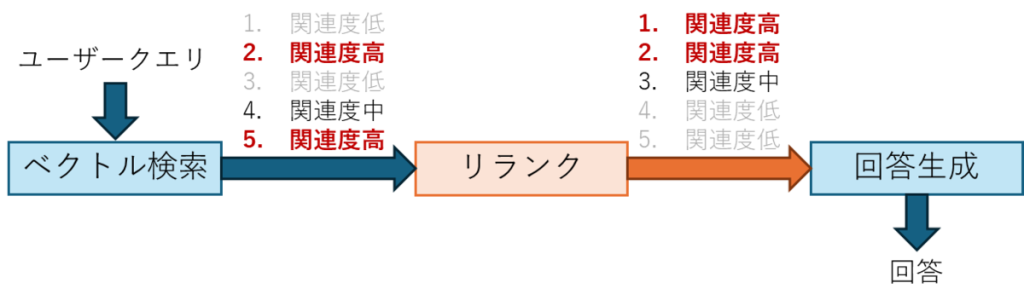
1.1 什么是重排序(Rerank)
在包含 Bedrock Knowledge Base 在内的 RAG 检索中,向量检索的应用十分广泛。
然而,仅依靠向量检索往往无法达到足够的检索精度,难以给出恰当的回答。
因此,对通过向量检索获取的文档进行重排序处理,可使相关度更高的文档出现在检索结果的靠前位置。
1.2 以往的实现方式
此前,要在 RAG 系统中集成重排序处理,需搭建 SageMaker 实例、托管重排序专用模型并执行推理。
例如,在 2024 年 8 月时,若要使用 Cohere Rerank 3,就需按照下述文章的说明创建 SageMaker 实例。
这种方式存在诸多问题,如需要投入精力准备 SageMaker 实例与重排序模型,且会产生运营成本。
1.3 Bedrock 支持的重排序模型
自 2024 年 12 月起,可通过 Bedrock 使用重排序模型。
借助该重排序模型,无需自行托管模型,仅通过调用 API 即可执行重排序操作。
这不仅省去了运营管理的繁琐工作,还无需一直启动服务器,只需根据使用量付费,让用户能轻松开启重排序功能的使用。
除了可通过 Bedrock 的 InvokeModel API 调用外,还支持通过 Bedrock Knowledge Base 的 Rerank API、Retrieve API、RetrieveAndGenerate API、RetrieveAndGenerateStream API 进行调用。
截至 2025 年 1 月,提供的模型有 Amazon Rerank 1.0(以下简称 Amazon Rerank 模型)和 Cohere Rerank 3.5(以下简称 Cohere Rerank 模型)。
2. 尝试应用重排序模型
本次验证将使用本文中已采用的、模拟酒店评论检索的数据。
此次以 “烤肉好吃的酒店” 为检索词,期望 “使用本地产蔬菜和肉类制作的烤肉料理” 的第 10 条评论以及 “炭火烤制的牛排” 的第 7 条评论能出现在检索结果的靠前位置。
重排序模型选用 Amazon Rerank 模型。
| 序号 | 内容 |
|---|---|
| 1 | 这家酒店的温泉堪称顶级疗愈。源泉直供的温泉水格外柔和,泡完后肌肤感觉滑溜溜的。从露天温泉能眺望到美丽的群山,夜晚还能一边泡澡一边欣赏满天繁星。这是一家让人想反复前往的温泉酒店。 |
| 2 | 酒店的温泉非常舒服,能让人彻底放松。室内温泉和露天温泉各具特色,尤其是从露天温泉看到的庭院景色美不胜收,可欣赏到四季不同的美景。水温也恰到好处,长时间浸泡也不会觉得疲惫。 |
| 3 | 早就听闻这是一家以温泉为特色的酒店,实际体验远超预期。因直接使用天然温泉源泉,水质极佳,泡完后身体持续暖暖的。我们还预约了私人温泉,在专属空间里度过了惬意的时光。 |
| 4 | 温泉区域宽敞开阔,视野极佳。从露天温泉能一览大海,可伴着海浪声悠闲度日。水温也不会过高,能慢慢暖遍全身,非常满意。此外,还支持当日往返使用,让人能轻松前来,这点很贴心。 |
| 5 | 温泉散发着令人舒心的硫磺香气,让人真切感受到来到了温泉胜地。温泉水功效显著,能明显感觉到肌肤变得光滑。这里有多个温泉池,有时特定时段还能独享,让人体验到奢华感。另外,泡完温泉后提供的冰镇饮品也是个惊喜服务。 |
| 6 | 酒店的餐食宛如艺术品。大量使用本地新鲜食材制作的怀石料理,不仅外观精美,每一道菜都能让人感受到制作的用心。尤其是用当季海鲜制作的刺身,堪称绝品,仅凭这一点就想再次前来。 |
| 7 | 晚餐有很多本地特色菜,非常满意。特别是炭火烤制的牛排,入口即化,美味得让人想一再续盘。早餐种类也很丰富,用本地蔬菜制作的沙拉和手工豆腐都很美味。 |
| 8 | 晚餐是套餐形式,每道菜都很好吃,其中最令人印象深刻的是用本地采摘的蔬菜制作的前菜和自制甜点。采用凸显食材本味的简单烹饪方式,充分展现了食材的优良品质。早餐营养均衡,刚出炉的面包尤其美味。 |
| 9 | 酒店的餐食超出预期。因靠近海边,大量使用新鲜海鲜,刺身和煮鱼都非常好吃。晚餐分量充足,每道菜的调味都饱含心意。早餐的日式料理也很美味,尤其是温泉蛋堪称绝品。 |
| 10 | 晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。 |
2.1 通过 Bedrock 的 InvokeModel API 使用
InvokeModel API 是用于调用 Bedrock 所提供模型的 API。
在请求体(body)中输入想要进行重排序的文档列表以及用户的查询语句后,就能在响应结果中获取到按与用户查询语句相关度从高到低重新排序的文档,以及各自的相关度(分数)。
代码
query = "烤肉好吃的酒店"
documents = [
"这家酒店的温泉堪称顶级疗愈。源泉直供的温泉水格外柔和,泡完后肌肤感觉滑溜溜的。从露天温泉能眺望到美丽的群山,夜晚还能一边泡澡一边欣赏满天繁星。这是一家让人想反复前往的温泉酒店。",
# (省略)
]
response = bedrock.invoke_model(
modelId="amazon.rerank-v1:0",
body=json.dumps({
"query": query,
"documents": documents,
"top_n": 3,
}),
)
body = json.loads(response["body"].read())
pprint.pprint(body["results"])
输出
[{'index': 9, 'relevance_score': 0.001466458403084568},
{'index': 6, 'relevance_score': 0.0005013742398679934},
{'index': 8, 'relevance_score': 0.0003640086870995012}]
※重排序结果中包含的索引(index)以 0 为起始,为了与上方表格保持一致,需在索引数值上加 1。
结果
| 序号 | 内容 |
|---|---|
| 10 | 晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。 |
| 7 | 晚餐有很多本地特色菜,非常满意。特别是炭火烤制的牛排,入口即化,美味得让人想一再续盘。早餐种类也很丰富,用本地蔬菜制作的沙拉和手工豆腐都很美味。 |
| 9 | 酒店的餐食超出预期。因靠近海边,大量使用新鲜海鲜,刺身和煮鱼都非常好吃。晚餐分量充足,每道菜的调味都饱含心意。早餐的日式料理也很美味,尤其是温泉蛋堪称绝品。 |
可以确认,正如预期的那样,第 10 条和第 7 条评论内容排在了靠前位置。
2.2 通过 Bedrock Knowledge Base 的 Rerank API 使用
Rerank API 是作为 Knowledge Base 的功能提供的,但其本质与上述的 InvokeModel 相同,输入文档列表和用户查询语句后,就能得到重排序后的文档列表。
代码
region = boto3.Session().region_name
amazon_rerank_arn = f"arn:aws:bedrock:{region}::foundation-model/amazon.rerank-v1:0"
response = bedrock_agent.rerank(
queries=[
{
"type": "TEXT",
"textQuery": {
"text": query,
},
},
],
sources=[
{
"inlineDocumentSource": {
"textDocument": {
"text": document,
},
"type": "TEXT",
},
"type": "INLINE",
} for document in documents
],
rerankingConfiguration={
"type": "BEDROCK_RERANKING_MODEL",
"bedrockRerankingConfiguration": {
"numberOfResults": 3,
"modelConfiguration": {
"modelArn": amazon_rerank_arn,
},
},
},
)
pprint.pprint(response["results"])
输出
[{'index': 9, 'relevanceScore': 0.0014664584305137396},
{'index': 6, 'relevanceScore': 0.0005013742484152317},
{'index': 8, 'relevanceScore': 0.0003640086797531694}]
可以确认,得到了与使用 InvokeModel 时完全相同的结果。
2.3 通过 Bedrock Knowledge Base 的 Retrieve API 使用
与 InvokeModel、Rerank API 不同,在 Retrieve API 中,无需传入文档列表作为输入。
该 API 以用户的查询语句为输入,先通过用户查询语句检索向量数据库,再将检索结果作为文档列表进行重排序。
为了使用 Retrieve API,我们先创建了知识库,并将上述内容逐条作为一个数据块进行存储。
首先确认不进行重排序时的结果。
代码
response = bedrock_agent.retrieve(
knowledgeBaseId=knowledgebase_id,
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 3,
"overrideSearchType": "SEMANTIC",
},
},
retrievalQuery={
"text": query,
},
)
pprint.pprint(response["retrievalResults"])
输出
[{'content': {'text': '酒店的餐食宛如艺术品。大量使用本地新鲜食材制作的怀石料理,不仅外观精美,每一道菜都能让人感受到制作的用心。尤其是用当季海鲜制作的刺身,堪称绝品,仅凭这一点就想再次前来。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/006.txt'},
'type': 'S3'},
'score': 0.43565163},
{'content': {'text': '酒店的餐食超出预期。因靠近海边,大量使用新鲜海鲜,刺身和煮鱼都非常好吃。晚餐分量充足,每道菜的调味都饱含心意。早餐的日式料理也很美味,尤其是温泉蛋堪称绝品。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/009.txt'},
'type': 'S3'},
'score': 0.435101},
{'content': {'text': '晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/010.txt'},
'type': 'S3'},
'score': 0.4281698}]
结果
| 序号 | 内容 |
|---|---|
| 6 | 酒店的餐食宛如艺术品。大量使用本地新鲜食材制作的怀石料理,不仅外观精美,每一道菜都能让人感受到制作的用心。尤其是用当季海鲜制作的刺身,堪称绝品,仅凭这一点就想再次前来。 |
| 9 | 酒店的餐食超出预期。因靠近海边,大量使用新鲜海鲜,刺身和煮鱼都非常好吃。晚餐分量充足,每道菜的调味都饱含心意。早餐的日式料理也很美味,尤其是温泉蛋堪称绝品。 |
| 10 | 晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。 |
当获取前 3 条结果时,第 10 条评论排在第 3 位,而第 7 条评论未出现在检索结果中。
若使用这样的检索结果进行 RAG,恐怕难以得到高精度的回答。
接下来,在 Retrieve API 中指定重排序模型,确认检索结果会发生怎样的变化。
代码
response = bedrock_agent.retrieve(
knowledgeBaseId=knowledgebase_id,
retrievalConfiguration={
"vectorSearchConfiguration": {
# (1) 首次检索时获取 10 条结果
"numberOfResults": 10,
"overrideSearchType": "SEMANTIC",
"rerankingConfiguration": {
"bedrockRerankingConfiguration": {
"modelConfiguration": {
"modelArn": amazon_rerank_arn,
},
# (2) 对检索得到的 10 条结果进行重排序,并返回前 3 条
"numberOfRerankedResults": 3,
},
"type": "BEDROCK_RERANKING_MODEL",
},
},
},
retrievalQuery={
"text": query,
},
)
pprint.pprint(response)
输出
[{'content': {'text': '晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/010.txt'},
'type': 'S3'},
'score': 0.0014721895568072796},
{'content': {'text': '晚餐有很多本地特色菜,非常满意。特别是炭火烤制的牛排,入口即化,美味得让人想一再续盘。早餐种类也很丰富,用本地蔬菜制作的沙拉和手工豆腐都很美味。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/007.txt'},
'type': 'S3'},
'score': 0.0004994205664843321},
{'content': {'text': '酒店的餐食超出预期。因靠近海边,大量使用新鲜海鲜,刺身和煮鱼都非常好吃。晚餐分量充足,每道菜的调味都饱含心意。早餐的日式料理也很美味,尤其是温泉蛋堪称绝品。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/009.txt'},
'type': 'S3'},
'score': 0.0003640086797531694}]
结果
| 序号 | 内容 |
|---|---|
| 10 | 晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。 |
| 7 | 晚餐有很多本地特色菜,非常满意。特别是炭火烤制的牛排,入口即化,美味得让人想一再续盘。早餐种类也很丰富,用本地蔬菜制作的沙拉和手工豆腐都很美味。 |
| 9 | 酒店的餐食超出预期。因靠近海边,大量使用新鲜海鲜,刺身和煮鱼都非常好吃。晚餐分量充足,每道菜的调味都饱含心意。早餐的日式料理也很美味,尤其是温泉蛋堪称绝品。 |
通过执行重排序,第 10 条和第 7 条内容占据了前 2 位。
这样一来,就能为用户提供更多其所需的信息了。
3. Amazon Rerank 模型与 Cohere Rerank 模型的对比
接下来,我们使用同样可在 Bedrock 上使用的 Cohere Rerank 模型对相同内容进行测试。
只需将 modelArn 替换为 Cohere Rerank 模型对应的 ARN,就能切换所使用的重排序模型。
操作起来非常简便。
代码
cohere_rerank_arn = f"arn:aws:bedrock:{region}::foundation-model/cohere.rerank-v3-5:0"
# (省略)
输出
[{'content': {'text': '晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/010.txt'},
'type': 'S3'},
'score': 0.3279808461666107},
{'content': {'text': '酒店的餐食宛如艺术品。大量使用本地新鲜食材制作的怀石料理,不仅外观精美,每一道菜都能让人感受到制作的用心。尤其是用当季海鲜制作的刺身,堪称绝品,仅凭这一点就想再次前来。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/006.txt'},
'type': 'S3'},
'score': 0.1456373631954193},
{'content': {'text': '晚餐有很多本地特色菜,非常满意。特别是炭火烤制的和牛牛排,入口即化,美味得让人想一再续盘。早餐种类也很丰富,用本地蔬菜制作的沙拉和手工豆腐都很美味。',
'type': 'TEXT'},
'location': {'s3Location': {'uri': 's3://xxx/007.txt'},
'type': 'S3'},
'score': 0.11919290572404861}]
结果
| 序号 | 内容 |
|---|---|
| 10 | 晚餐是大量使用本地食材制作的创意料理,每道菜都能感受到巧思。特别是用本地产蔬菜和肉类制作的烤肉料理,堪称绝品,充分凸显了食材本身的味道。早餐也很用心,有手工果酱和刚出炉的面包等,非常满意。 |
| 6 | 酒店的餐食宛如艺术品。大量使用本地新鲜食材制作的怀石料理,不仅外观精美,每一道菜都能让人感受到制作的用心。尤其是用当季海鲜制作的刺身,堪称绝品,仅凭这一点就想再次前来。 |
| 7 | 晚餐有很多本地特色菜,非常满意。特别是炭火烤制的和牛牛排,入口即化,美味得让人想一再续盘。早餐种类也很丰富,用本地蔬菜制作的沙拉和手工豆腐都很美味。 |
与使用 Amazon Rerank 模型时相比,第 7 条的排名下降了一位,但仍在前三之列。
第 6 条内容虽然是关于海鲜料理而非肉类料理的评论,但它是关于美味料理的评论,而非温泉相关,因此我认为其得分较高。
这样一来,在 RAG 生成回答时,也能在不缺失信息的情况下进行内容生成了。
4. 其他
4.1 调用速度
我们对 Amazon Rerank 模型与 Cohere Rerank 模型的响应速度是否存在差异进行了验证。
针对俄勒冈区域的模型,我们分别对相同请求各执行 5 次,通过比较响应时间的平均值来分析差异。
Amazon Rerank 模型
| 序号 | 响应时间(秒) |
|---|---|
| 1 | 0.895 |
| 2 | 0.687 |
| 3 | 0.734 |
| 4 | 0.828 |
| 5 | 0.775 |
| 平均 | 0.784 |
Cohere Rerank 模型
| 序号 | 响应时间(秒) |
|---|---|
| 1 | 0.454 |
| 2 | 0.508 |
| 3 | 0.533 |
| 4 | 0.495 |
| 5 | 0.453 |
| 平均 | 0.489 |
对比结果显示,Cohere Rerank 模型的速度约为 Amazon Rerank 模型的 1.5 倍。
4.2 费用
本次使用的模型费用如下表所示。
虽然相较于非重排序模型(例如 Amazon Nova Lite 为每 1000 个输出令牌 0.00024 美元),这些重排序模型的费用略显偏高,但这也意味着仅通过 API 调用就能使用到如此复杂的功能。
| 序号 | 模型 | 费用 |
|---|---|---|
| 1 | Amazon Rerank 模型 | 1 美元 / 1000 次查询 |
| 2 | Cohere Rerank 模型 | 2 美元 / 1000 次查询 |
总结
我们对 Bedrock 新增的重排序模型进行了验证,确认其对改善检索结果具有实际作用。
实验表明,通过执行重排序操作,能够使更贴合用户输入的内容出现在检索结果的靠前位置。
此外,Bedrock Knowledge Base 的优势在于,无需自行开发实现,仅通过修改设置就能实现检索效果的大幅提升。
本次验证仅进行到检索(retrieve)阶段,而若使用 retrieve_and_generate 功能,还可将回答生成的过程也交由 Bedrock 完成。
未来,我希望活用 Bedrock 的重排序功能,开发出更贴合用户意图的 RAG 系统。
发表回复