近年来,以 LLM(大语言模型)、VLM(视觉语言模型)为代表的基础模型被大量公开。与图像、自然语言处理等领域不同,基础模型也正逐步应用于时间序列建模领域。
本文将为大家介绍时间序列基础模型之一 ——“Chronos-Bolt”。
关于 Chronos-Bolt
简单来说,Chronos 是一款通过预先学习各类时间序列数据,无需对目标应用数据进行额外学习,即可实现时间序列预测的时间序列基础模型。而 Chronos-Bolt 是 Chronos 的后续迭代模型,与初代 Chronos 相比,其预测精度和运行性能均有大幅提升。
参考资料 ,Chronos 相关论文链接:arxiv.org
本文中,我们将借助 AutoGluon 框架,实现基于 Chronos-Bolt 的时间序列预测流程。AutoGluon 是由 AWS 主导开发的开源 AutoML(自动化机器学习)框架,该框架已集成多款时间序列预测模型,Chronos-Bolt 便是其中之一。
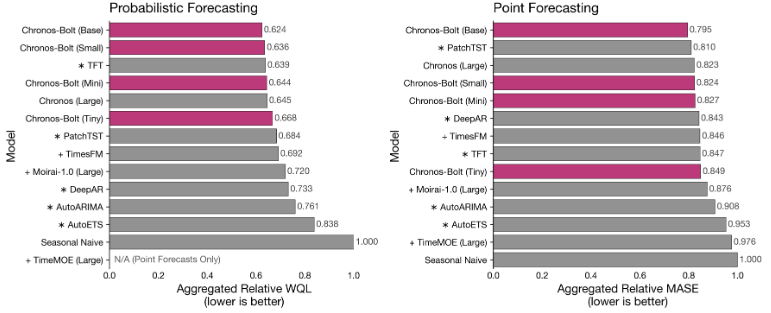
1. 无需训练即可实现高精度推理
为实现 “无需训练即可预测” 的能力,Chronos/Chronos-Bolt 不仅学习了各类真实时间序列数据,还采用了 TS-Mixup、KernelSynth 等合成数据生成技术,通过大量时间序列数据的训练,确保即使在缺乏目标领域训练数据的情况下,也能保证一定的预测精度。
通常而言,提升预测精度需要针对目标数据进行训练,但 Chronos-Bolt 在无训练数据的场景下,仍可实现符合预期的预测精度。
2. 相比 Chronos 模型速度更快(最高达 260 倍)
初代 Chronos 模型每次仅能预测未来 1 个时间步的结果;而 Chronos-Bolt 通过 “同时对多个时间步(t、t+1、t+2……)进行推理” 的设计,实现了速度优化。根据 AWS 官方博客的基准测试数据,在模型规模与 Chronos 相同的情况下,Chronos-Bolt 的运行性能最高可达到 Chronos 的 260 倍。

3. 相比 Chronos 模型精度更高
根据官方基准测试结果,Chronos-Bolt 的预测精度优于初代 Chronos 模型。仅从这一点来看,选择 Chronos-Bolt 也具备显著优势。
基于 Chronos-Bolt 的时间序列预测
本文将介绍三种基于 Chronos-Bolt 的预测实现方案,具体如下:
| 方案 | 说明 |
|---|---|
| 零样本推理 | 不进行额外训练,直接基于预训练模型进行预测 |
| 执行微调 | 基于目标数据进行训练后,再开展预测 |
| 利用回归模型进行特征外推 | 除预测目标时间序列外,额外引入辅助特征用于预测 |
前期准备
1. 安装所需库
要使用 Chronos-Bolt,需提前安装 autogluon 库,执行以下命令即可:
pip install autogluon
2. 数据准备
本文使用的数据集为 Kaggle 平台公开的 “Store Sales – Time Series Forecasting”数据集,该数据集包含厄瓜多尔零售商 “Corporación Favorita” 的商品销量数据。
数据集链接:www.kaggle.com
由于原始数据格式难以直接适用,我们将在后续实现中对数据进行处理。
import polars as pl
transaction = pl.read_csv("./data/store-sales-time-series-forecasting/transactions.csv")
holiday = pl.read_csv("./data/store-sales-time-series-forecasting/holidays_events.csv")
transaction = transaction.join(holiday, how="left", on="date")
transaction = transaction.fill_null("null")
transaction = transaction.with_columns(
pl.col("date").str.to_date()
)
transaction = transaction.with_columns(
pl.col("date").dt.month().alias("month"),
pl.col("date").dt.day().alias("day"),
pl.col("date").dt.weekday().alias("weekday")
)
df = transaction
train_df = df.filter(
pl.col("date").dt.year() < 2017
)
train_df.write_csv("./data/train.csv")
valid_df = df.filter(
(pl.col("date").dt.year() >= 2017) & (pl.col("date").dt.month() == 1)
)
valid_df = pl.concat([train_df, valid_df], how="diagonal_relaxed")
valid_df.write_csv("./data/valid.csv")
以下是本分析中使用的主要参数说明:
| 项目(列名) | 说明 |
|---|---|
| date | 日期 |
| store_nbr | 店铺编号 |
| transactions | 交易量(★本次预测目标值) |
| type | 节假日或事件类型 |
| locale | 适用区域范围 |
| locale_name | 具体区域名称(如城市、省份等) |
| month | 从 date 列中提取的月份 |
| day | 从 date 列中提取的日期 |
| weekday | 从 date 列中提取的星期几 |
零样本推理
零样本推理的实现非常简单,通过以下代码即可完成:
其中,id_column指定用于分组的类别列,timestamp_column指定时间列,target指定预测目标列。在TimeSeriesPredictor.fit方法中,通过指定presets="bolt_base",即可调用 Chronos-Bolt 模型。此外,将bolt_base替换为bolt_small或bolt_tiny,还可使用不同规模的 Chronos-Bolt 模型。
import polars as pl
from autogluon.timeseries import TimeSeriesDataFrame, TimeSeriesPredictor
train_data = TimeSeriesDataFrame.from_path(
"data/train.csv",
id_column="store_nbr",
timestamp_column="date",
)
predictor = TimeSeriesPredictor(prediction_length=30, freq="D", target="transactions").fit(train_data, presets="bolt_base")
predictions = predictor.predict(train_data)
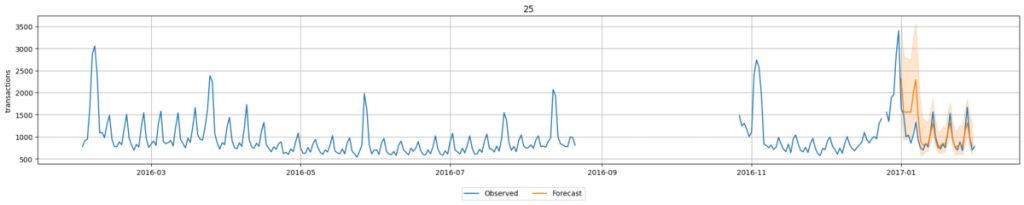
推理结果可视化
AutoGluon 提供了用于可视化的工具函数,我们将使用该函数展示结果。尽管数据中存在部分临时缺失,但可以看出:即使不进行额外训练,模型也基本能贴合实际数据趋势。
test_data = TimeSeriesDataFrame.from_path(
"data/valid.csv",
id_column="store_nbr",
timestamp_column="date",
)
predictor.plot(test_data,predictions,max_history_length=365,item_ids=[25])
本图表中,蓝色线条代表实际交易量数据,橙色线条代表 Chronos-Bolt 的预测结果。此外,橙色线条前后的阴影部分表示80% 置信区间。
微调
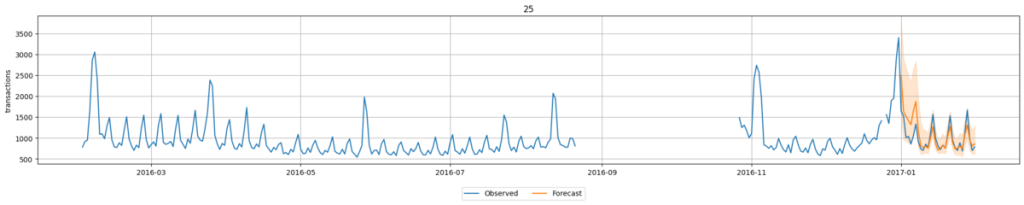
接下来,我们通过微调训练模型,并用其尝试时间序列预测。微调可通过以下代码实现:此代码会生成两种模型:零样本模型与微调模型。在hyperparameters的Chronos键下,通过列表定义了两种模型配置,核心要点是将fine_tune参数设为True。
predictor = TimeSeriesPredictor(prediction_length=31, eval_metric="MASE", freq="D", target="transactions").fit(
train_data,
hyperparameters={
"Chronos": [
{"model_path": "bolt_base", "ag_args": {"name_suffix": "ZeroShot"}},
{"model_path": "bolt_base", "fine_tune": True, "ag_args": {"name_suffix": "FineTuned"}},
]
},
enable_ensemble=False,
time_limit=600,
)训练结束后,可通过以下实现代码获取零样本模型与微调后模型的评估结果。
predictor.leaderboard(test_data)
此外,利用上述实现的预测器,还可按以下方式进行预测并可视化结果:
predictions = predictor.predict(train_data, model=”ChronosZeroShot[bolt_base]”)
predictor.plot(test_data,predictions,max_history_length=365,item_ids=symbols, max_num_item_ids=len(symbols))
对比零样本推理结果可见,微调后的模型预测结果更贴合实际数据趋势。
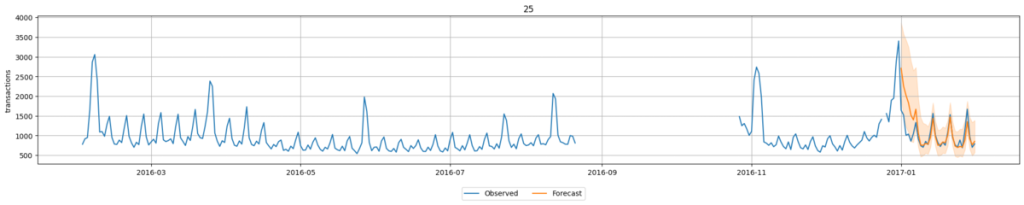
特征外推的使用
在部分场景中,除了预测目标时间序列数据外,还可能存在可辅助预测的其他时间序列数据。例如,店铺销量可能与影响到店人数的 “降水量” 相关,这类数据即可作为辅助特征使用。但需注意:外推需使用 “预测当日” 的辅助特征数据,因此在实际验证中,若无法获取当日辅助数据,则难以进行当日预测(例如:若需在预测前日使用次日的准确降水量数据,实际场景中通常无法实现)。
外推场景下的预测公式
回归预测值 = Chronos-Bolt 的预测值 + CatBoost(外推回归模型)的预测值
代码实现
核心修改点在于:在TimeSeriesPredictor中通过known_covariates_names指定用于外推的辅助特征列。本次模型中,我们输入了日期特征(month、day、weekday)与节假日信息(type、locale、locale_name),具体实现如下:
predictor = TimeSeriesPredictor(
prediction_length=31,
eval_metric="MASE",
target="transactions",
known_covariates_names=["type", "locale", "locale_name", "month", "day", "weekday"],
freq="D"
).fit(
train_data,
hyperparameters={
"Chronos": [
{"model_path": "bolt_base", "ag_args": {"name_suffix": "ZeroShot"}},
{
"model_path": "bolt_base",
"covariate_regressor": "CAT",
"target_scaler": "standard",
"ag_args": {"name_suffix": "WithRegressor"},
},
],
},
time_limit=600,
enable_ensemble=False,
)
与微调场景类似,可通过以下代码对比模型效果:
predictor.leaderboard(test_data)
在本次预测中,需要提供用于外推的特征量。由于此类推理需要 31 天的完整数据才能进行(若数据不完整则难以实现),因此我们筛选出店铺编号为 25 的完整数据集,并用其对推理结果进行可视化。具体实现代码如下。
filtered_id_df = train_data.to_data_frame().loc[25]
filtered_id_df['item_id'] = 25
filtered_id_df['timestamp'] = filtered_id_df.index
train_data = TimeSeriesDataFrame.from_data_frame(filtered_id_df)
filtered_id_df = test_data.to_data_frame().loc[25]
filtered_id_df['item_id'] = 25
filtered_id_df['timestamp'] = filtered_id_df.index
test_data = TimeSeriesDataFrame.from_data_frame(filtered_id_df)
predictions = predictor.predict(train_data, model="ChronosWithRegressor[bolt_base]",
known_covariates =test_data
)
predictor.plot(test_data,predictions,max_history_length=365,
item_ids=[25], max_num_item_ids=1)对比微调模型可见,加入外推特征后的预测结果更接近实际数据趋势。
总结
我们通过 AutoGluon 轻松调用了 Chronos-Bolt 模型,并尝试完成了时间序列预测。将 LLM 等基础模型的思路应用到时间序列模型中,这一方向非常有趣,其未来发展值得期待。
发表回复