
今天我尝试了使用 Amazon Bedrock Knowledge Bases,并将 Amazon Aurora PostgreSQL 用作向量数据库。
去年 12 月,Amazon Bedrock Knowledge Bases 新增了可快速创建 Aurora PostgreSQL 作为向量数据库的功能,大幅简化了设置流程。
本次我也将利用这一快速创建功能进行设置。
1. 将 Aurora PostgreSQL 配置为向量存储
事前准备
本次将 S3 用作 RAG(检索增强生成)的外部数据源。之后,我们会确认 LLM(大语言模型)的回答是否参考了存储在 S3 中的资料。
Knowledge Bases 的创建
在 AWS 管理控制台中,进入 Bedrock 页面,仅通过 GUI 操作即可轻松创建 Knowledge Bases。
点击 “Knowledge Base with vector store”(带向量存储的知识库),即可跳转至 Knowledge Bases 创建页面。
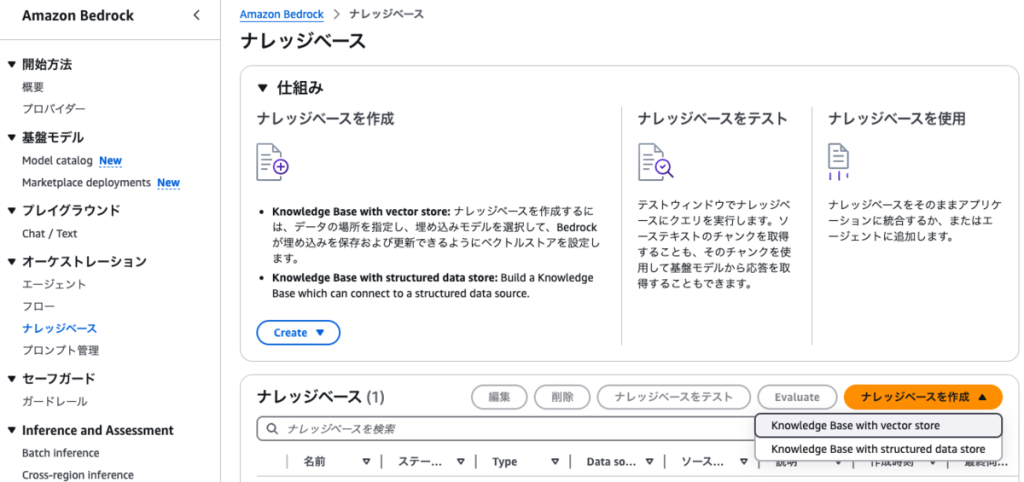
在 “步骤 2 配置数据源” 中,指定事前准备好的 S3 的 URI。而 “步骤 3 选择嵌入模型并配置向量数据库” 则是本次的核心内容。
向量数据库的选项中新增了 “Amazon Aurora PostgreSQL Serverless” 这一项目,请选择此项。
※向量数据库的可选范围因区域而异,本文中测试使用的是东京区域。
之后点击 “下一步”,确认创建内容后即可完成设置。仅需通过 GUI 操作即可完成,直观又简单!
在 RDS 控制台中可以确认已创建的数据库。

数据库表的创建情况如下所示。
Bedrock_Knowledge_Base_Cluster=> \d bedrock_knowledge_base
Table "bedrock_integration.bedrock_knowledge_base"
Column | Type | Collation | Nullable | Default
-----------+---------------------+-----------+----------+---------
id | uuid | | not null |
embedding | public.vector(1536) | | |
chunks | text | | |
metadata | jsonb | | |
Indexes:
"bedrock_knowledge_base_pkey" PRIMARY KEY, btree (id)
"bedrock_knowledge_base_embedding_idx" hnsw (embedding public.vector_l2_ops)
Knowledge Bases 的测试
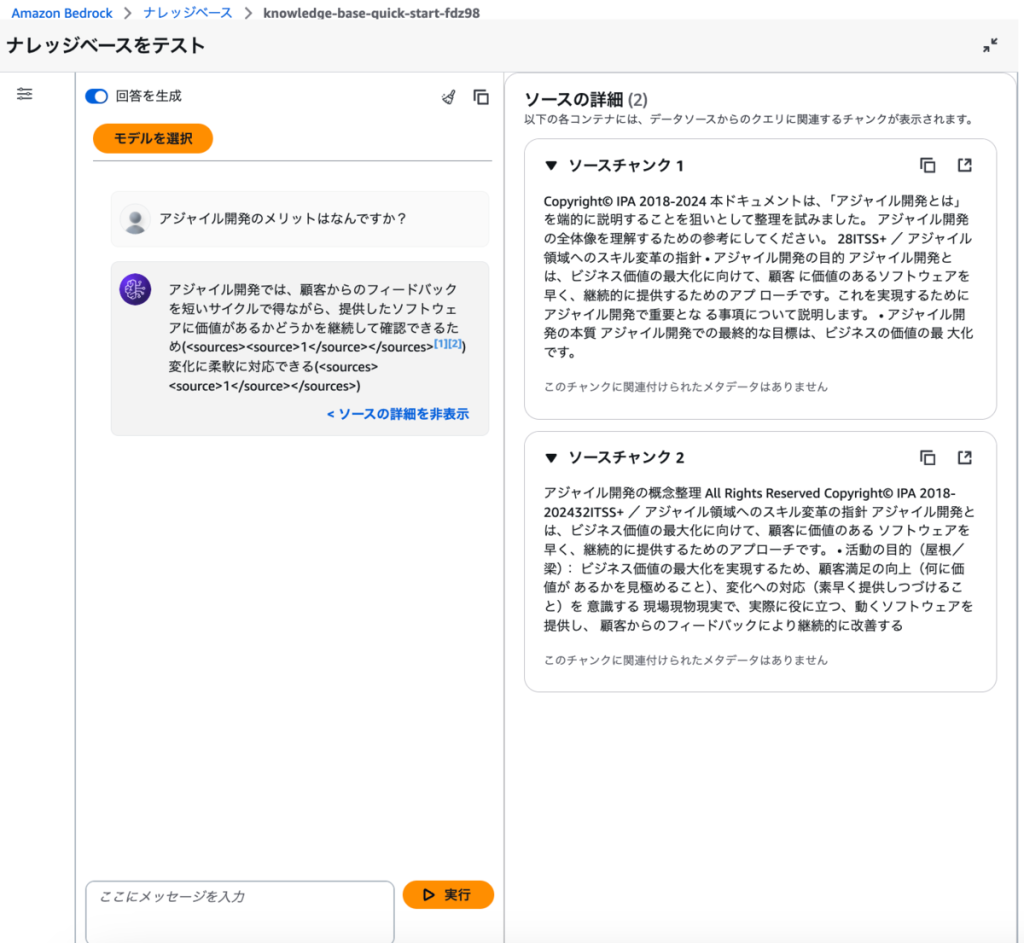
选择已创建的 Knowledge Bases 后,会出现 “测试知识库”页面。在此处向 LLM 提问,测试是否能返回预期的回答。
本次我提出了 “敏捷开发的优势是什么?“ 这一问题。结果如预期般返回了参考了事前准备并存储在 S3 中的资料的回答,看起来运行正常。
2. 与 OpenSearch Serverless 的对比
OpenSearch Serverless 是被广泛用作向量数据库的代表性服务。此处将整理其与 Aurora Serverless v2 在实际使用中的差异。
功能
当使用 Aurora PostgreSQL 作为向量数据库时,仅支持语义搜索这一种检索类型。
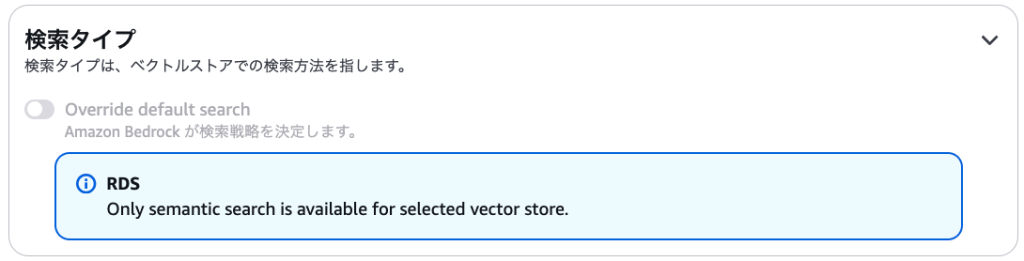
而使用 OpenSearch Serverless 时,则可在混合搜索与语义搜索之间进行选择。
- 语义搜索:并非简单的关键词匹配,而是检索语义上相关的信息。
- 混合搜索:将关键词检索与语义搜索相结合进行信息检索。
从检索功能性来看,OpenSearch Serverless 更具优势。若需融入关键词检索功能,建议选择 OpenSearch Serverless。
成本
OpenSearch Serverless 的计算费用采用计时收费模式,即便处于未使用状态,仍会产生每小时的费用。以美国东部(弗吉尼亚北部)区域为例,每个单位的费用为 0.24 美元 / 小时。根据文档说明,至少会按 2 个单位计费,因此每月的费用约为 0.24 美元 / 小时 × 720 小时 × 2 = 345 美元。
相比之下,Aurora Serverless v2 不仅单价低廉(0.12 美元 / 单位 / 小时),还支持缩容至 0 个单位。因此,能够有效控制未使用状态下的成本。
查看此前通过快速创建功能搭建的 Aurora PostgreSQL 实例配置,确认其确实支持缩容至 0 个单位,与预期一致。

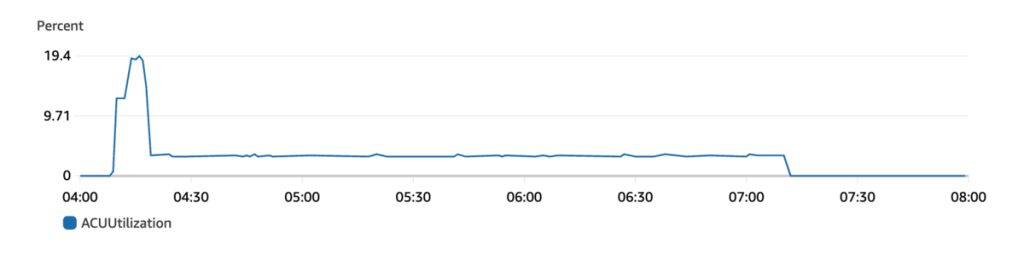
在 CloudWatch 中查看单位使用率(ACU),可以确认实例在未使用时会自动缩容至 0 个单位。
3. 检索速度确认
最后,我们将验证文档数量增加时的检索速度及 ACU(Aurora 计算单位)变化情况。数据源采用 Kaggle 上的 “BBC News Summary” 数据集,将约 9000 条数据存储至 S3 中。
参照 “1. 将 Aurora PostgreSQL 配置为 Bedrock Knowledge Bases 的向量数据库” 中的方法,向 LLM 发起提问。结果显示,与文档数量较少时相同,回答在数十毫秒内即可返回。对于本次使用的数据集规模而言,检索速度似乎不存在明显问题。
查看 ACU 数据可知:文档导入时的 ACU 使用率约为 30%(16(最大扩容单位数)× 0.3 = 5 个单位),LLM 生成回答时的 ACU 使用率约为 15%(16 × 0.15 = 2.5 个单位)。

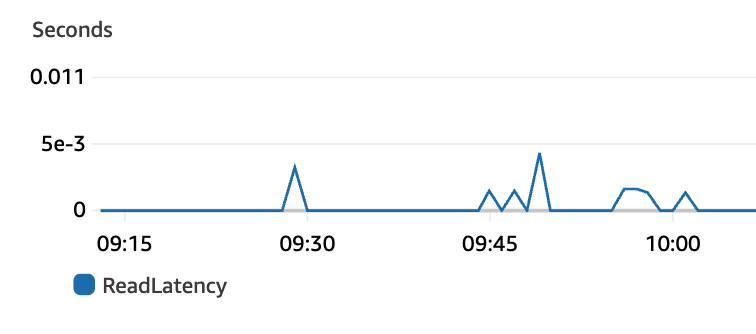
向量数据库的 ReadLatency(读取延迟)控制在 0.01 秒以内,使用体验较为流畅。
4. 总结
本次尝试了在 Bedrock Knowledge Bases 中使用 Aurora Serverless v2 作为向量数据库。
借助快速创建功能,仅需几次 GUI 点击操作,即可轻松完成向量数据库的搭建。对于 “控制未使用状态下成本” 这一需求,也能够轻松实现。
最后提醒
仅删除 Bedrock Knowledge Bases,并不能移除通过快速创建功能生成的向量数据库等其他关联资源。若不再需要这些资源,请务必手动删除,避免遗漏。
发表回复