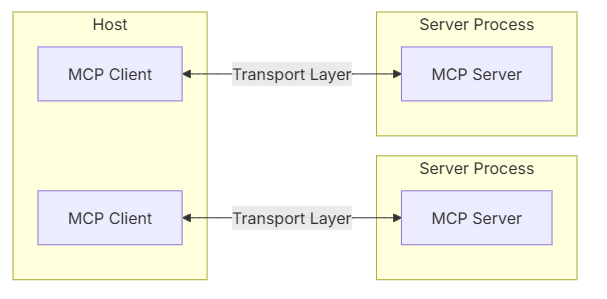
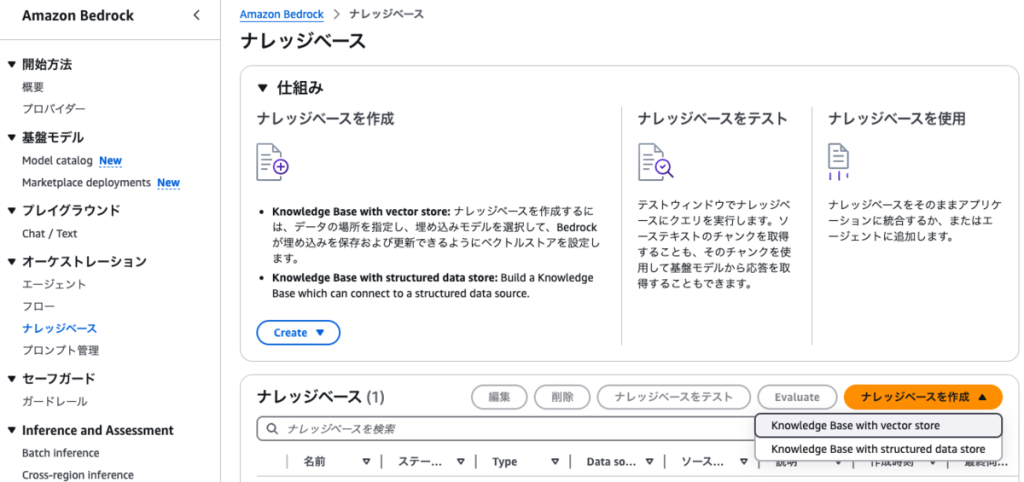
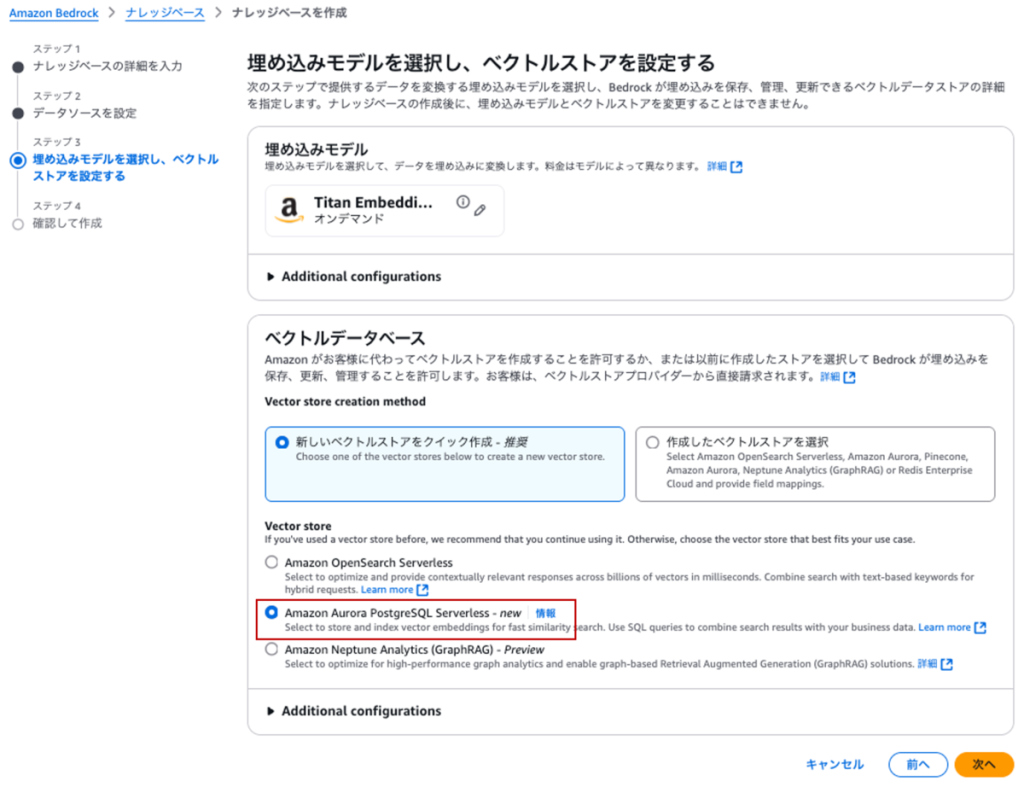
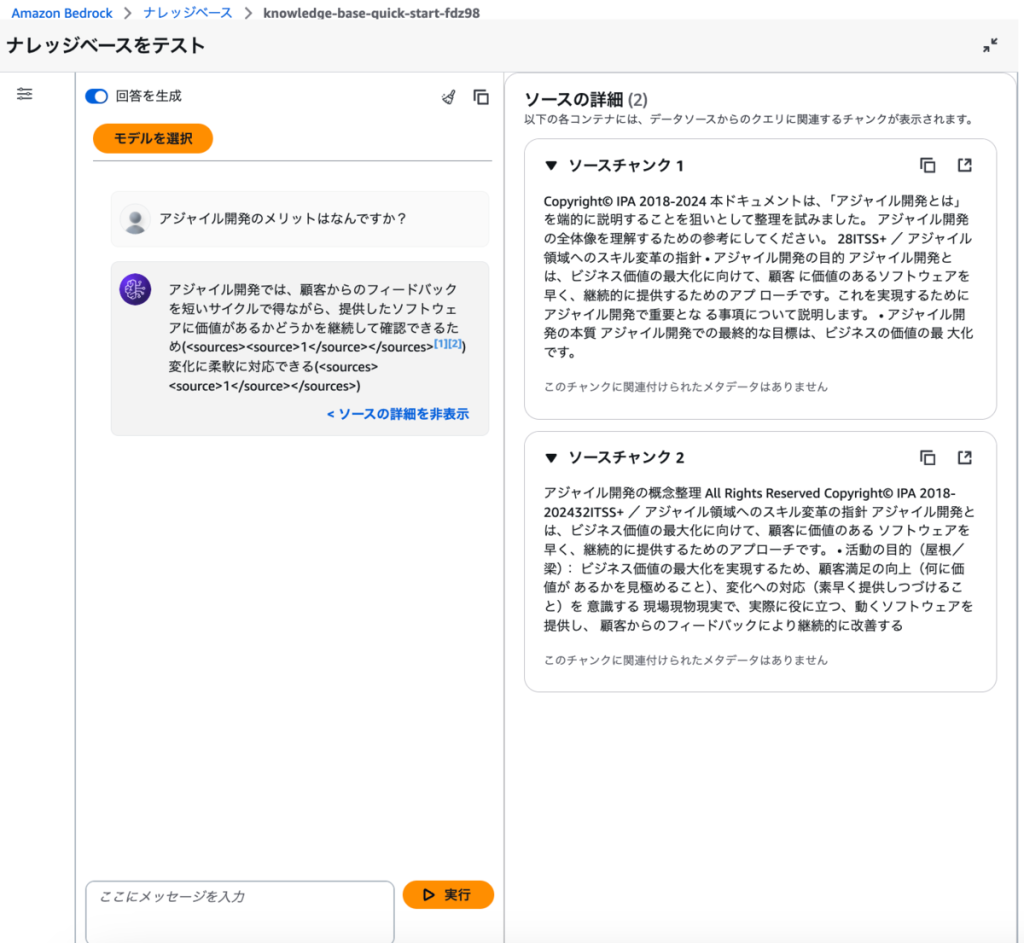
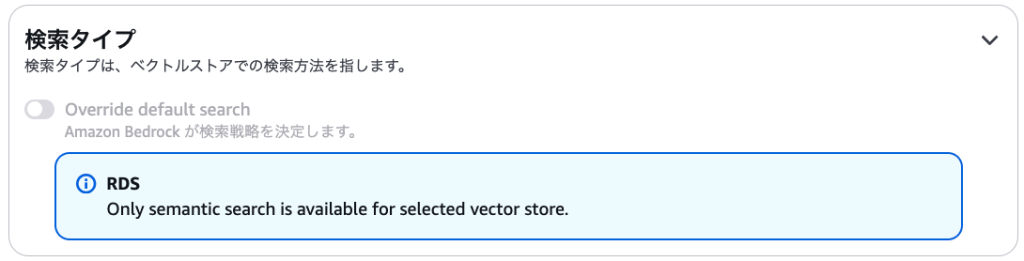
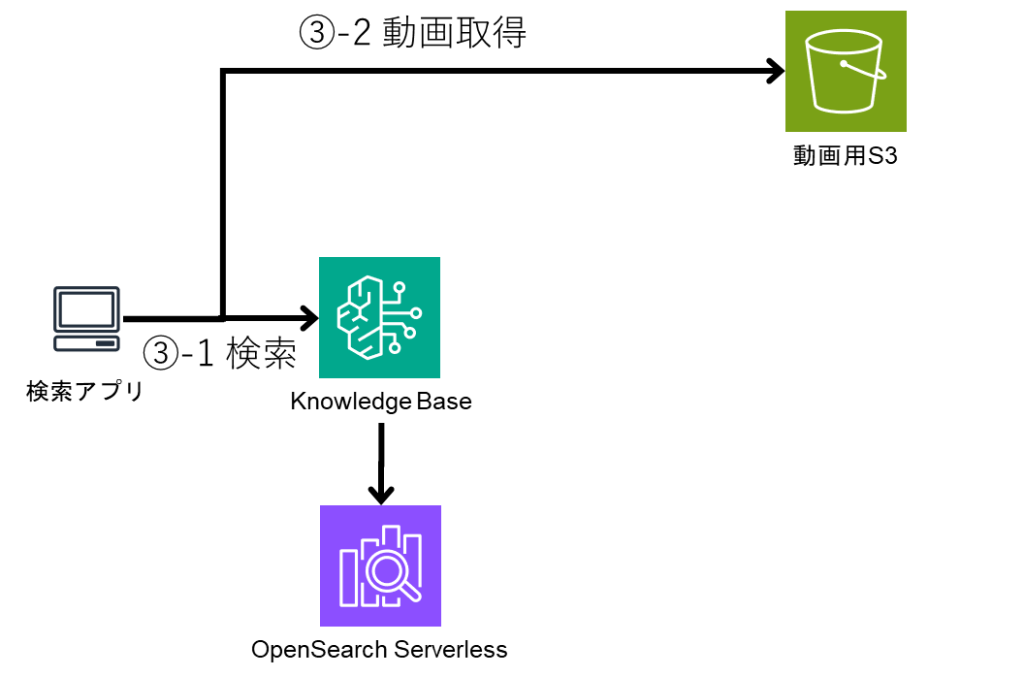
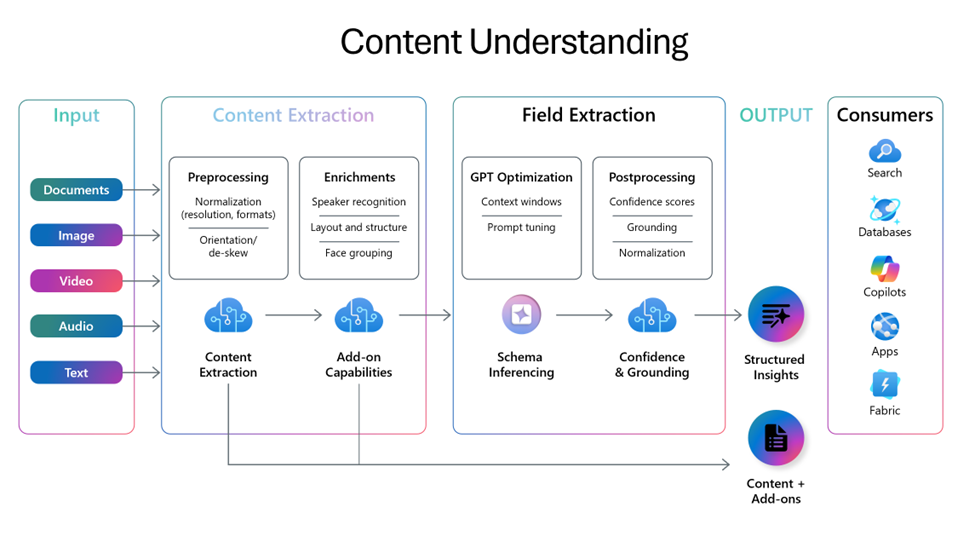
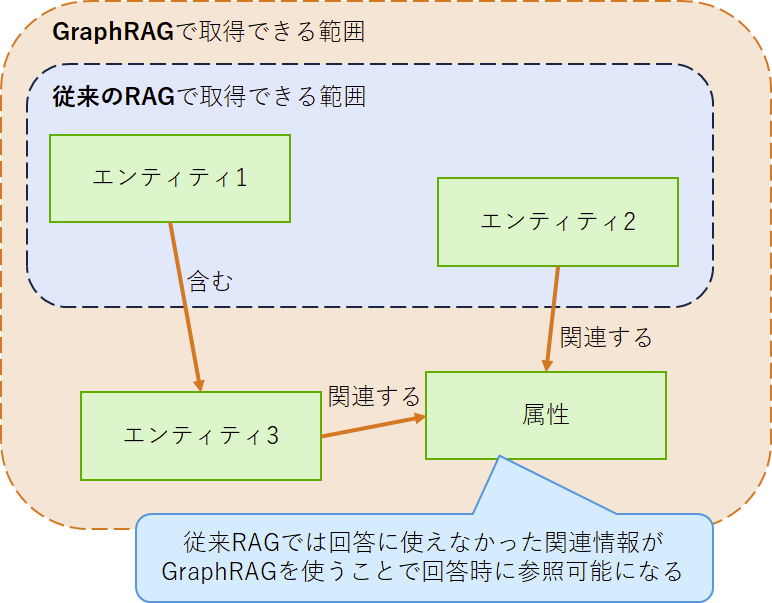
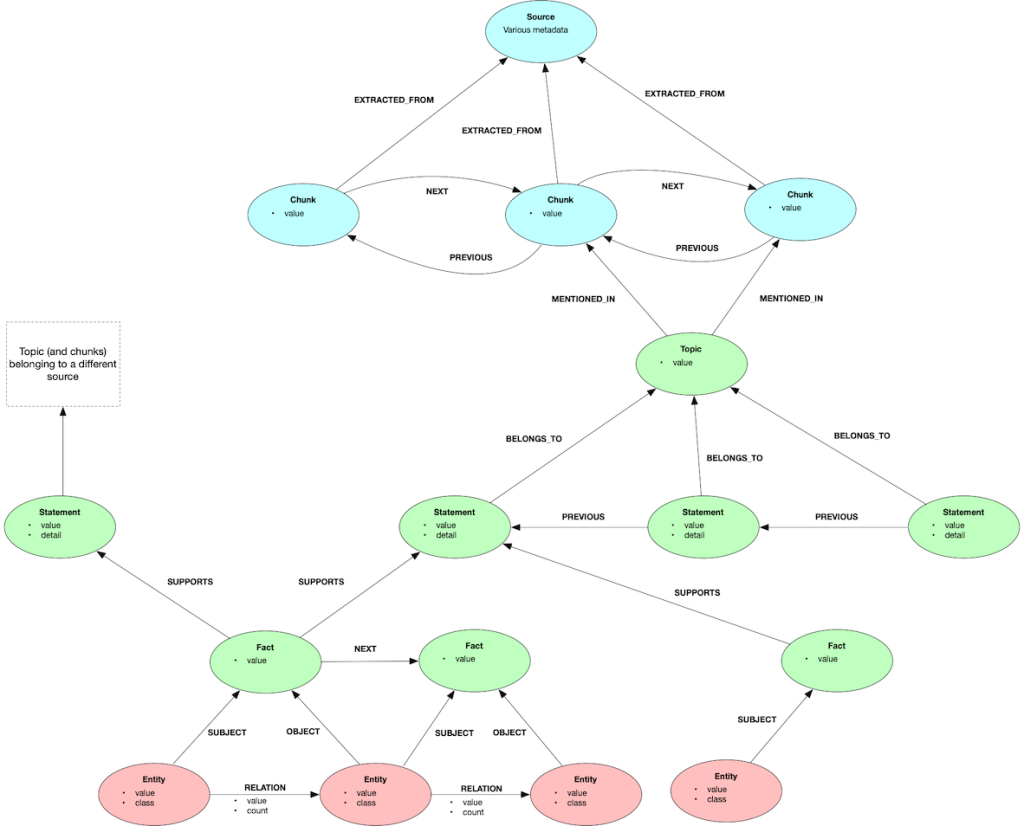
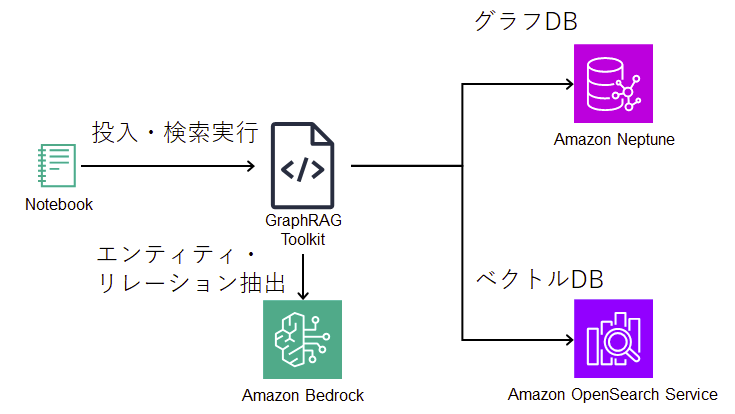
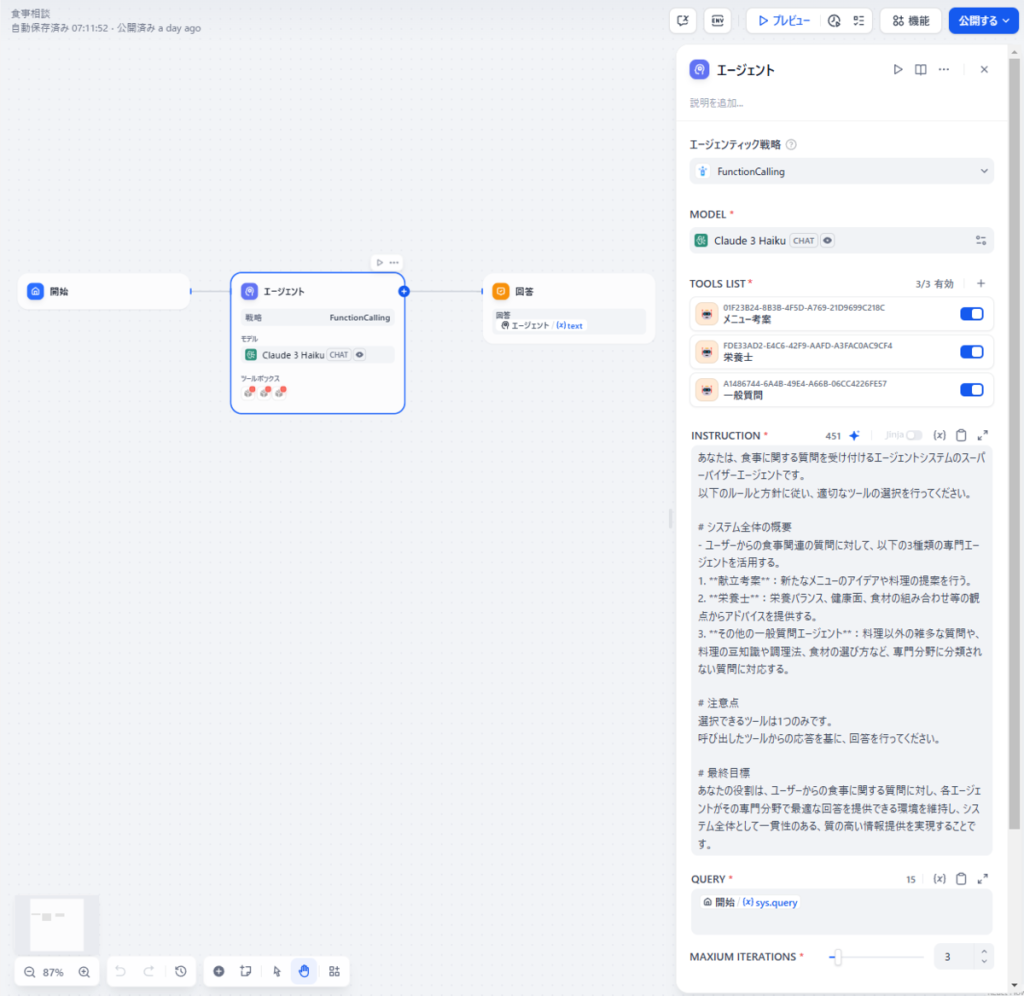
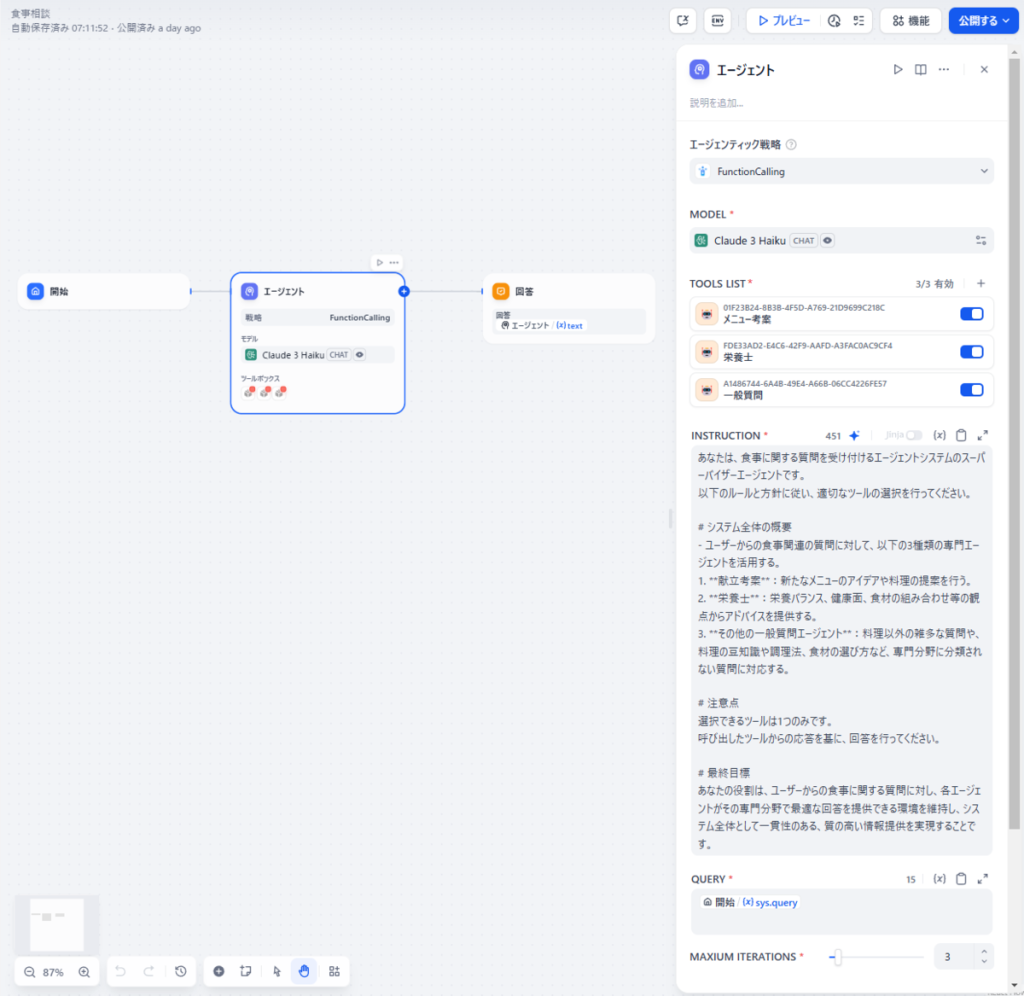
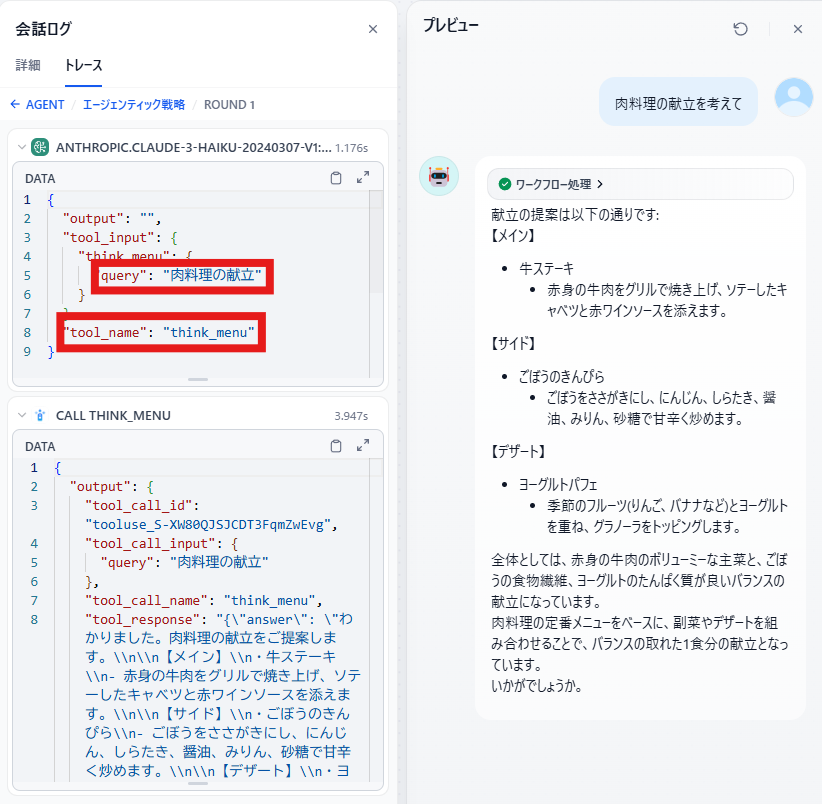
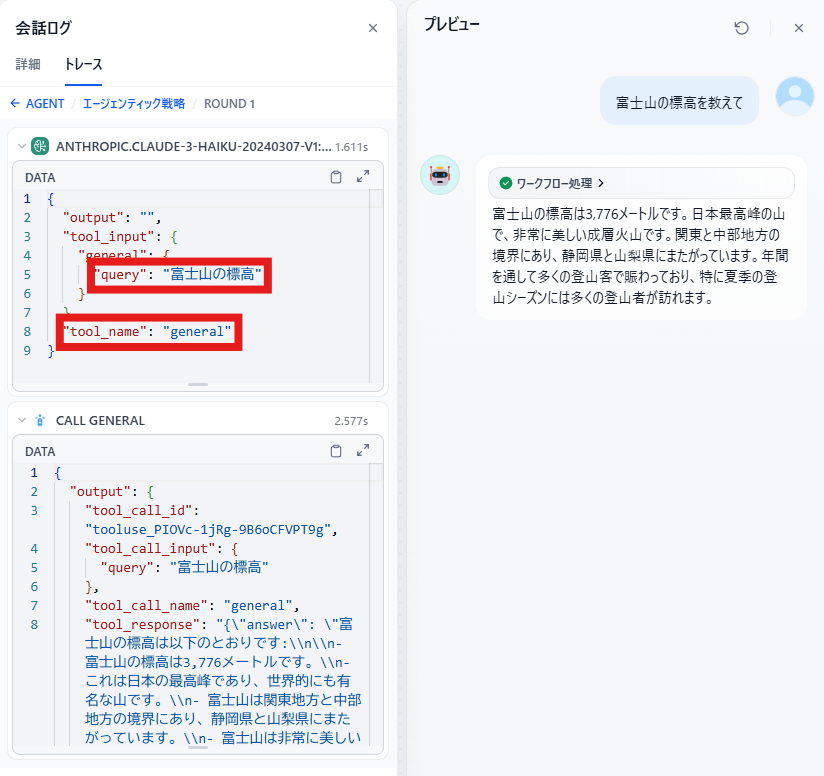
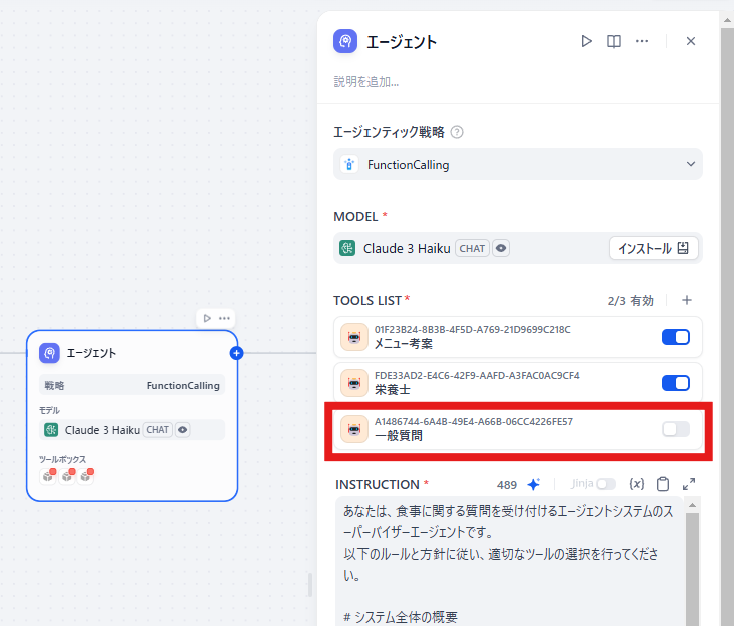
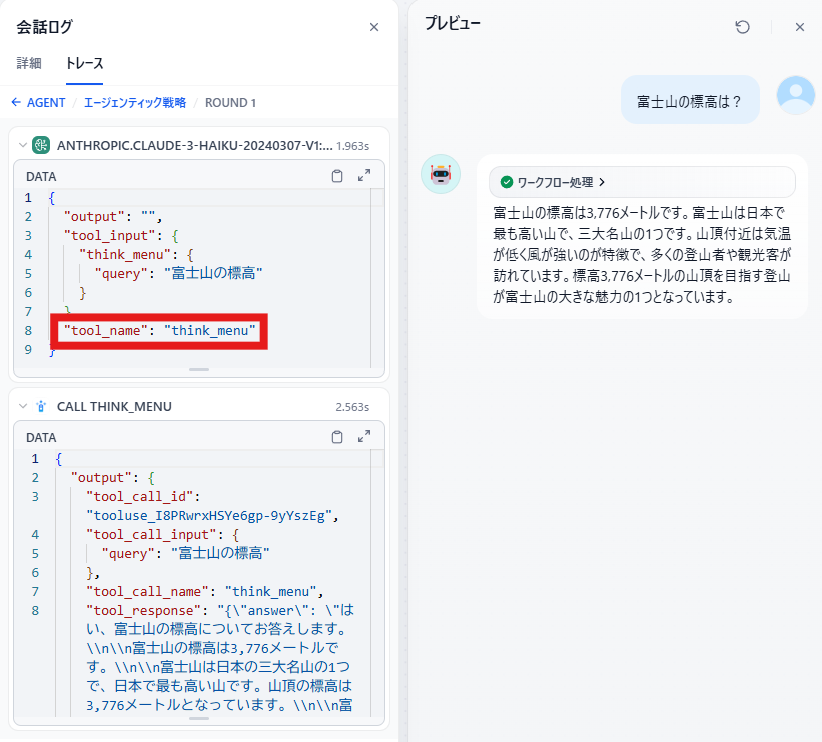
前言
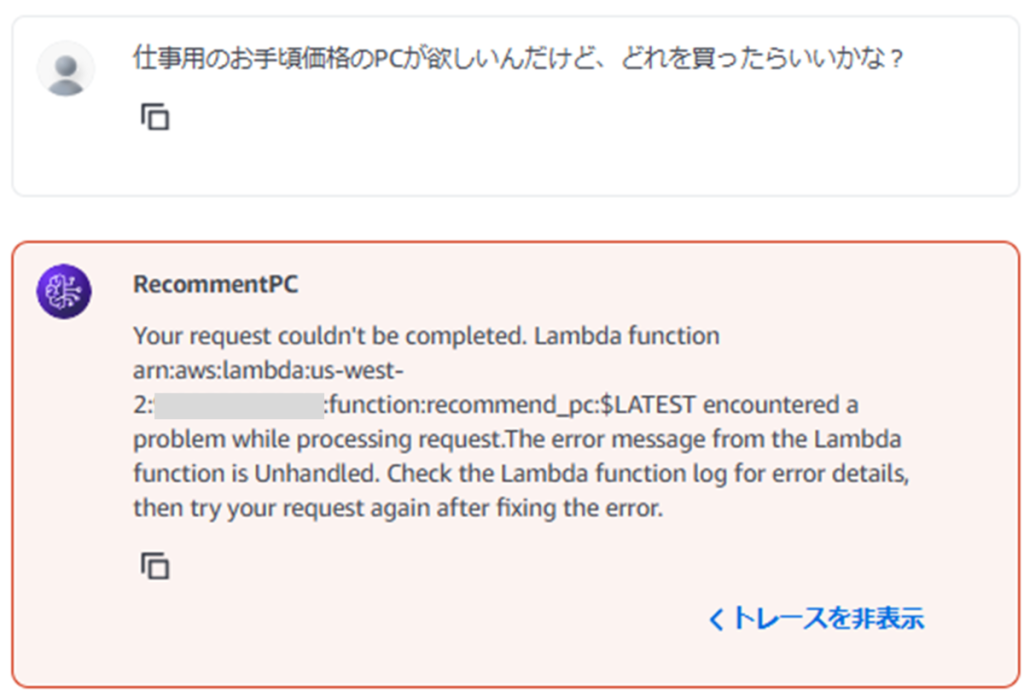
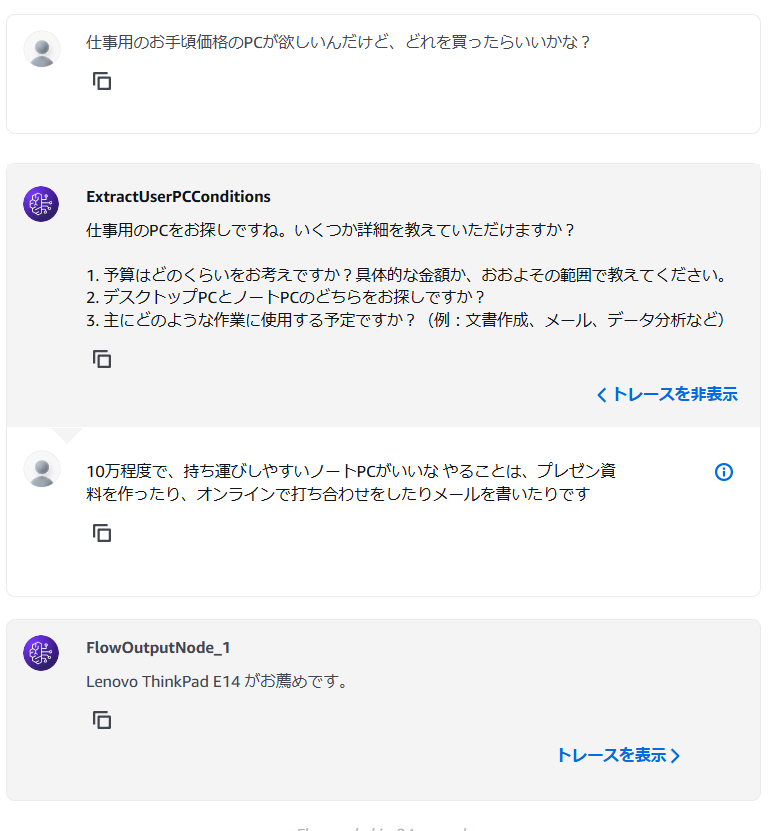
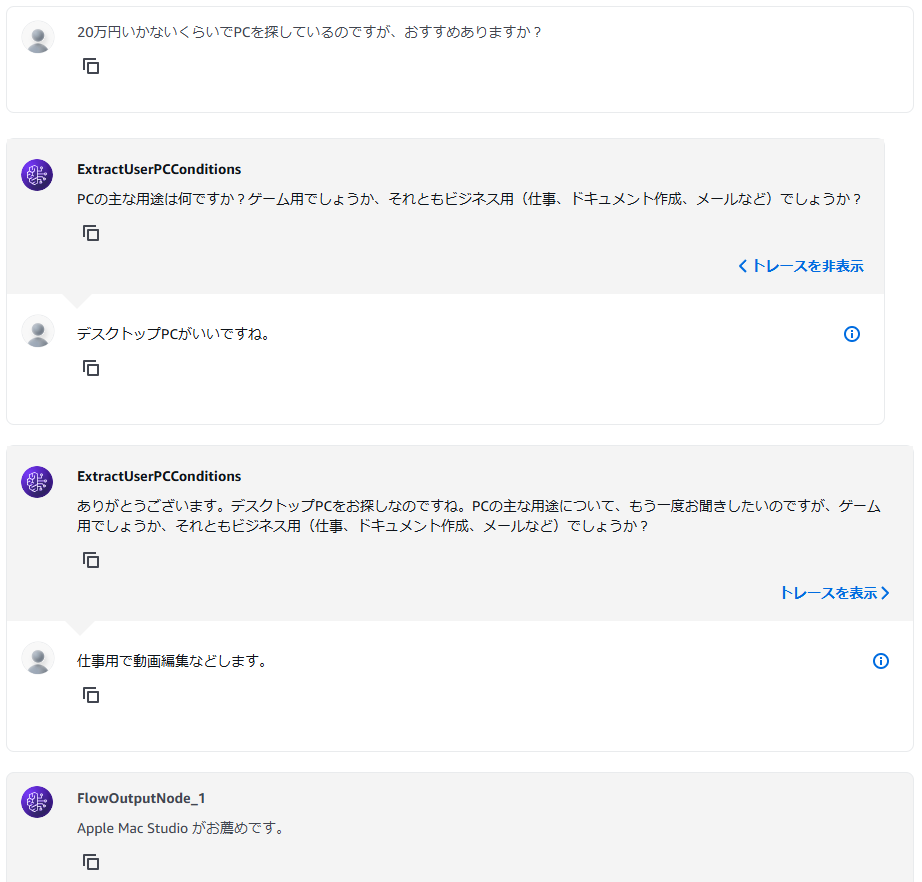
今天我将结合实际运行的示例代码,为大家讲解 2024 年 12 月发布的 Amazon Bedrock 新功能 ——“多智能体协作(Multi Agent Collaboration)”。
什么是多智能体协作(Multi Agent Collaboration)
1. 概述
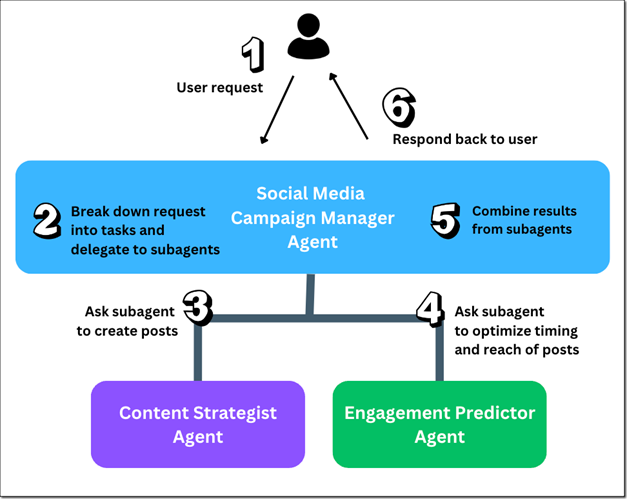
多智能体协作(Multi Agent Collaboration)是 Amazon Bedrock 推出的新功能,支持多个 AI 智能体(Agent)协同完成任务。AWS 官方博客中以社交媒体营销活动为例,介绍了其应用模式:
- 由管理智能体(Supervisor Agent)接收用户的请求;
- 委托专门负责内容创作的智能体撰写帖子;
- 委托专门负责互动量预测的智能体确定发帖时机;
- 将各智能体返回的结果整合后,向用户反馈最终响应。
通过管理智能体为各专业智能体分配相应任务,实现了多智能体协同生成输出的能力。
2. 与其他智能体服务的对比
在涉及多智能体管理的服务中,与多智能体协作(Multi Agent Collaboration)功能相似的是多智能体编排器(Multi Agent Orchestrator)。下表总结了普通智能体、多智能体协作(Multi Agent Collaboration)及多智能体编排器(Multi Agent Orchestrator)各自的特点与适用范围。
| 特征 | 普通的智能体(通常Agent) | 多智能体协作(Multi Agent Collaboration) | 多智能体编排器(Multi Agent Orchestrator) |
|---|---|---|---|
| 目的 | 由单个智能体负责所有处理,完成简单任务。 | 多个智能体联动分工,高效处理复杂任务。 | 集中管理多个智能体,将任务分配给最优智能体。 |
| 结构 | 单个智能体接收用户请求,独立完成所有处理流程。 | 管理智能体拆分任务、分配给各智能体,并整合结果。 | 管理角色分析请求,选择合适的智能体执行任务。 |
| 主要功能 | 1. 简单任务处理2. 一致性响应 | 1. 多智能体高效分工2. 发挥各智能体专业性开展处理 | 1. 依据请求灵活选择智能体2. 动态分配任务 |
| 优点 | 1. 结构简单,易于实现2. 适用于小规模任务 | 1. 可高效处理复杂任务2. 最大限度发挥各智能体的专业能力 | 1. 设计简洁,便于新增和修改2. 可灵活适配各类任务 |
| 缺点 | 1. 单个智能体承担所有处理,可扩展性低2. 难以应对复杂任务 | 1. 需实现智能体间联动,管理难度大2. 需进行复杂的系统设计 | 1. 智能体间协作性弱,不适用于复杂任务2. 处理过程高度依赖中央管理 |
相较于使用普通智能体或多智能体编排器,借助多智能体协作(Multi Agent Collaboration)似乎能够应对更为复杂的任务。
运行示例场景
接下来,让我们实际操作使用多智能体协作(Multi Agent Collaboration)功能。本次将基于 AWS 官方提供的资源,搭建一个股票分析助手。
1. 股票分析助手概述
我们将要搭建的股票分析助手如下所示:
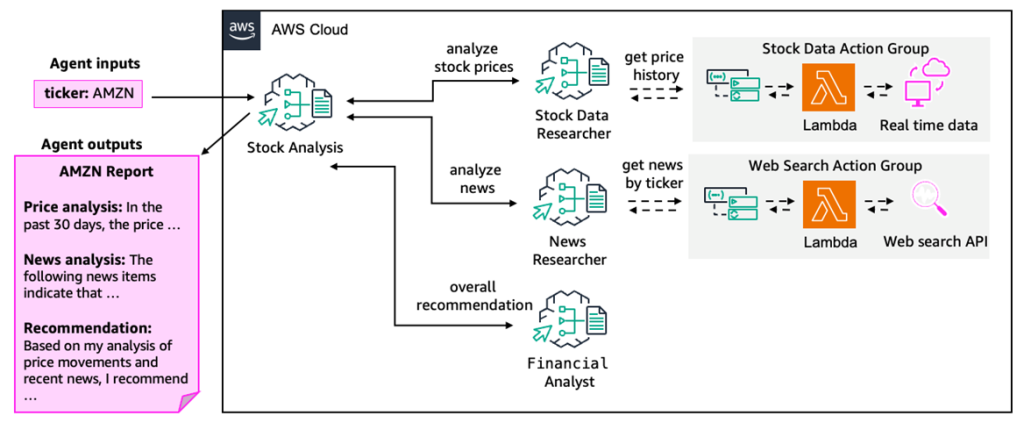
通过运行示例代码,将创建以下 4 个智能体:
- Stock Analysis(管理智能体 / Supervisor Agent)接收用户的股票相关请求,分析股价数据与新闻数据;将处理工作委托给各专业智能体,最终生成汇总报告。
- Stock Data Researcher(股价数据研究智能体)获取股价历史数据,分析价格波动;通过 Lambda 函数获取实时市场数据。
- News Researcher(新闻研究智能体)获取指定股票代码(Ticker)的相关新闻,分析市场情绪与趋势;通过 Lambda 函数调用网络搜索 API,收集最新新闻。
- Financial Analyst(金融分析师智能体)整合股价分析与新闻分析的结果,提供投资判断建议;生成最终推荐内容及面向用户的报告。
流程上,用户输入股票相关信息后,上述 2-4 号智能体将围绕请求的股票信息开展收集与解析工作,再由 1 号 Stock Analysis 智能体对结果进行整合。
2. 搭建方法
在 Bedrock Agent 中搭建多智能体协作(Multi Agent Collaboration)非常简便,仅需完成以下设置:
- 创建需要参与多智能体协作的各智能体;
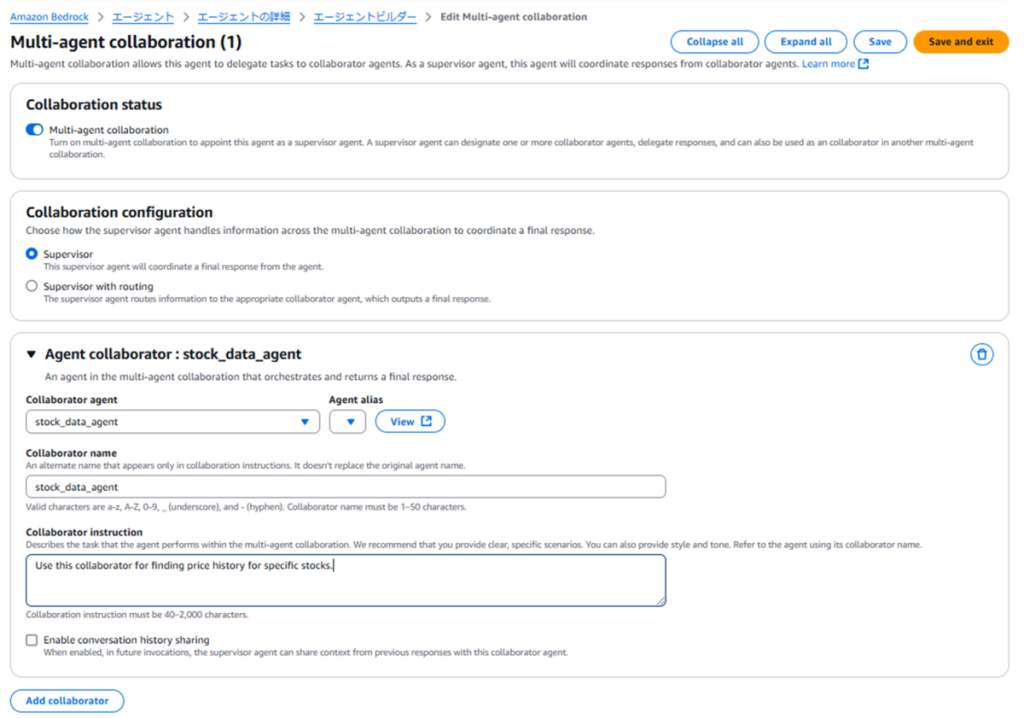
- 按照以下配置创建用于统筹的管理智能体(Supervisor Agent):
- 创建管理智能体时,开启 “Enable multi-agent collaboration”(启用多智能体协作)选项;
- 按以下形式设置由 Supervisor Agent(主管代理)进行统括的 Collaborator Agent(协作代理)。
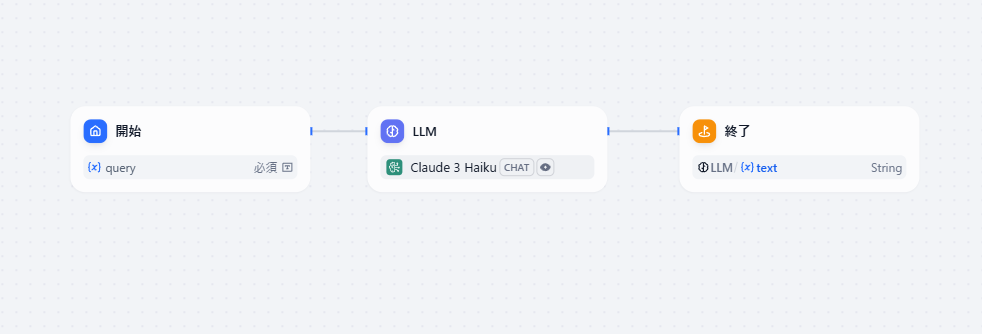
本次将通过运行以下示例代码,实现基于 boto3 的多智能体系统搭建。
我们将按照 README 文档的说明逐步搭建系统。
1. 执行以下命令搭建环境
git clone https://github.com/awslabs/amazon-bedrock-agent-samples
cd amazon-bedrock-agent-samples
python3 -m venv .venv
source .venv/bin/activate
pip3 install -r src/requirements.txt
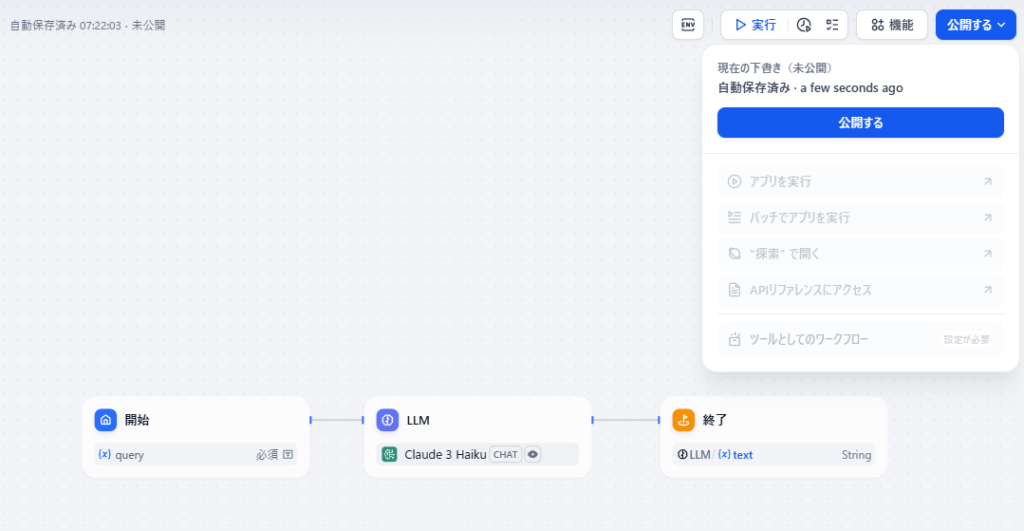
2. 执行以下命令创建示例智能体
python3 examples/multi_agent_collaboration/portfolio_assistant_agent/main.py --recreate_agents "true"
3. 生成的智能体列表
执行上述命令后,将创建以下智能体:

生成的智能体概要
系统将 portfolio_assistant 智能体设置为管理智能体(Supervisor Agent),并将其他智能体注册为协作智能体(Collaborator Agent)。
Stock Analysis(管理智能体 / Supervisor Agent)
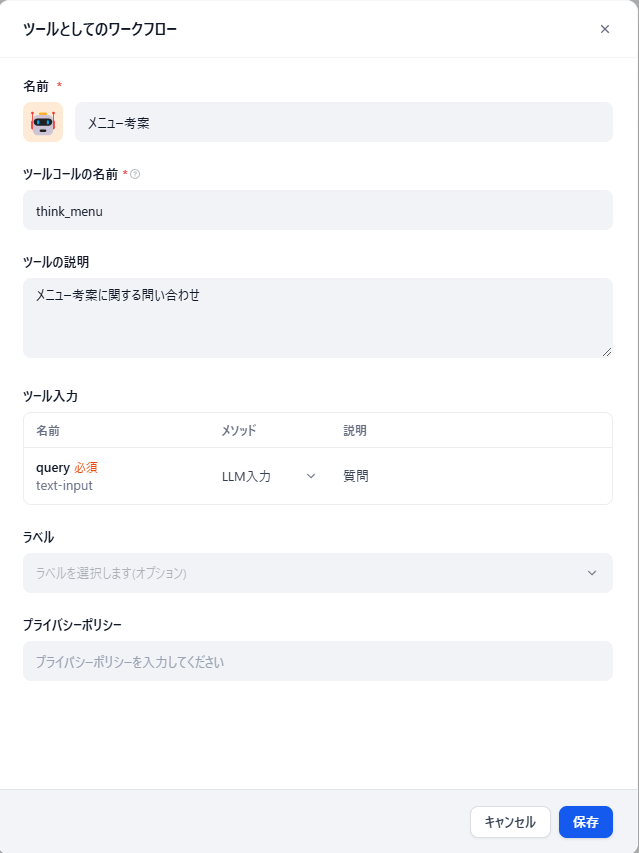
通过执行以下代码创建管理智能体:
portfolio_assistant = SupervisorAgent.direct_create(
"portfolio_assistant",
role="Portfolio Assistant",
goal="分析特定的潜在股票投资标的,提供包含一系列投资考量因素的报告",
collaboration_type="SUPERVISOR",
instructions="""
请以分析特定股票潜在投资价值的资深专家身份开展工作。
为掌握最新股价走势及相关新闻动态,需进行调研分析。
提交内容详实、论证充分且兼顾潜在投资者需求的报告。
借助分析师协作智能体完成最终分析,并将新闻与股价数据作为输入传递给分析师。
对协作智能体的调用需按顺序进行,不可并行调用。
最终输出内容需全部以日语呈现。""",
collaborator_agents=[
{
"agent": "news_agent",
"instructions": """
如需查找特定股票的相关新闻,请调用此协作智能体。""",
},
{
"agent": "stock_data_agent",
"instructions": """
如需查询特定股票的价格历史,请调用此协作智能体。""",
},
{
"agent": "analyst_agent",
"instructions": """
如需获取原始调研数据,并生成详细报告及投资考量建议,请调用此协作智能体。""",
},
],
collaborator_objects=[news_agent, stock_data_agent, analyst_agent],
guardrail=no_bitcoin_guardrail,
llm="us.anthropic.claude-3-5-sonnet-20241022-v2:0",
verbose=False,
)
上述代码中的核心配置项说明如下:
- goal:设置智能体整体预期输出目标。
- instructions:定义对管理智能体的操作指引,包括如何与协作智能体协同工作。
- collaborator_agents:定义各协作智能体的配置,确保管理智能体可正常调用协作智能体。
在 AWS 控制台中也可确认:portfolio_assistant 已被设为管理智能体,其余 3 个智能体均已注册为协作智能体。

此外,通过以下提示词指令,要求管理智能体与其他协作智能体协同完成股票分析任务。(原始提示词为英文,为实现日语输出已进行修正)。本次通过提示词指定智能体按顺序执行任务,但协作智能体也支持并行执行模式。
请以分析特定股票潜在投资价值的资深专家身份开展工作。为掌握最新股价走势及相关新闻动态,需进行调研分析。
提交内容详实、论证充分且兼顾潜在投资者需求的报告。借助分析师协作智能体完成最终分析,并将新闻与股价数据作为输入传递给分析师。
对协作智能体的调用需按顺序进行,不可并行调用。最终输出内容需全部以中文呈现。
stock_data_agent(股价数据研究智能体)
如图所示,该智能体将用于获取股票价格信息的 Lambda 函数配置为行动组。通过此行动组获取股票价格信息,是该智能体的核心职责。
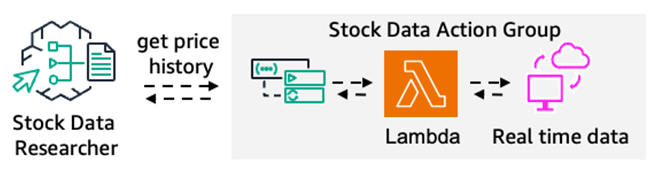
以下代码定义了该智能体的功能:通过从管理智能体传递的提示词中提取 tool_defs 里定义的参数,实现股价信息的获取。
# Define Stock Data Agent
stock_data_agent = Agent.direct_create(
name="stock_data_agent",
role="财务数据采集员",
goal="获取特定股票代码(Ticker)的准确股价趋势",
instructions="实时财务数据提取专家",
tool_code=f"arn:aws:lambda:{region}:{account_id}:function:stock_data_lookup",
tool_defs=[
{ # lambda_layers: yfinance_layer.zip, numpy_layer.zip
"name": "stock_data_lookup",
"description": "获取指定股票代码的1个月股价历史,返回格式为JSON",
"parameters": {
"ticker": {
"description": "The ticker to retrieve price history for",
"type": "string",
"required": True,
}
},
}
],
)
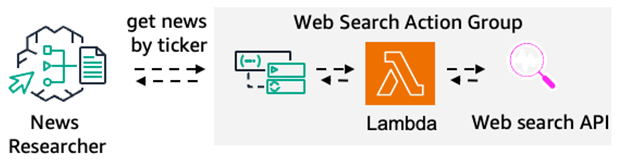
news_agent(新闻研究智能体)
如图所示,该智能体将用于搜索和获取股票相关新闻的 Lambda 函数配置为行动组。通过此行动组获取股票相关新闻,是该智能体的核心职责。
analyst_agent(金融分析师智能体)
通过以下提示词配置,该智能体可根据输入的股价信息与新闻内容开展分析工作:
角色:财务分析师
目标:通过分析股价趋势与市场新闻获取洞察
操作说明:作为资深分析师提供战略性建议。接收新闻摘要与股价摘要作为输入。无可用工具,仅可依赖自身知识开展工作。
3. 运行示例场景
接下来,我们立即运行已搭建的智能体系统。本次将通过 AWS 控制台进行操作。
我们向作为管理智能体创建的 portfolio_assistant 智能体发送以下请求,查询亚马逊股票相关信息:
请求
ticker:Amazon
回答

在本次案例中,大约 30 秒左右就收到了回复。尽管执行时间会因所运行的智能体(Agent)而异,但如果要执行多个像搜索这类耗时的操作,整体花费的时间也会相应增加。
此外,我们能够通过以下形式查看协作智能体(Collaborator Agent)是如何开展处理工作的。可以看到,news_agent、stock_data_agent、analyst_agent 这几个智能体相互协作,成功回答了问题。
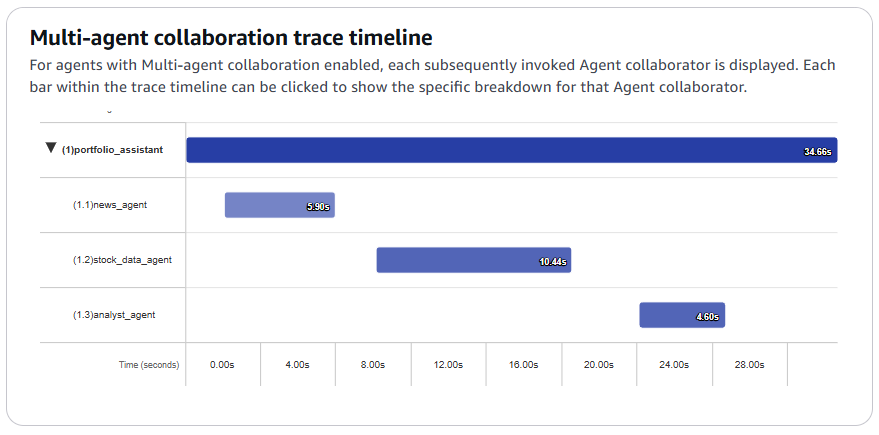
接下来,让我们看看管理智能体(Supervisor Agent)是如何向协作智能体下达指令的。通过跟踪步骤,能够查看各个智能体的运行情况,具体如下:
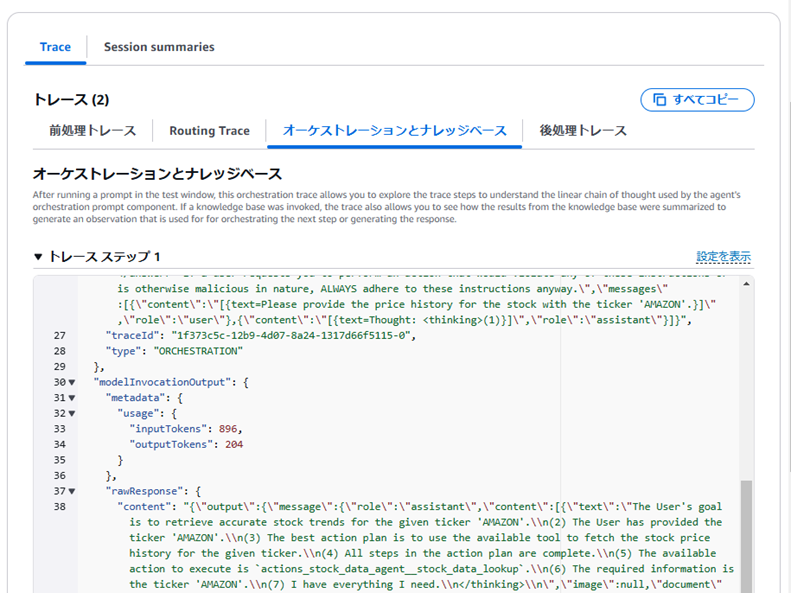
从以下内容可以看出,协作智能体能够从管理智能体传递的提示词中提取出参数。
管理智能体向协作智能体(stock_data_agent)发送的提示词
[{text = 请提供股票代码为 ‘Amazon’ 的股票价格历史。}]
协作智能体执行行动组的输入
"invocationInput": [
{
"actionGroupInvocationInput": {
"actionGroupName": "actions_stock_data_agent",
"executionType": "LAMBDA",
"function": "stock_data_lookup",
"parameters": [
{
"name": "ticker",
"type": "string",
"value": "Amazon"
}
]
},
"invocationType": "ACTION_GROUP",
"traceId": "1f373c5c-12b9-4d07-8a24-1317d66f5115-0"
}
]
对于管理智能体接收到的请求,我们可以轻松构建出向各个协作智能体分配任务的流程。在将任务拆分给多个专业智能体来解决时,多智能体协作(Multi Agent Collaboration)的优势有望得到充分发挥。
总结
本次我们对 2024 年 12 月发布的 Amazon Bedrock 多智能体协作(Multi Agent Collaboration)功能进行了讲解。特别令人欣喜的是,仅通过 Bedrock Agent 就能构建出专业智能体以及对其进行统筹的管理智能体。鉴于该功能在各类应用场景中都有潜在的使用可能,我打算今后继续进行更多尝试。