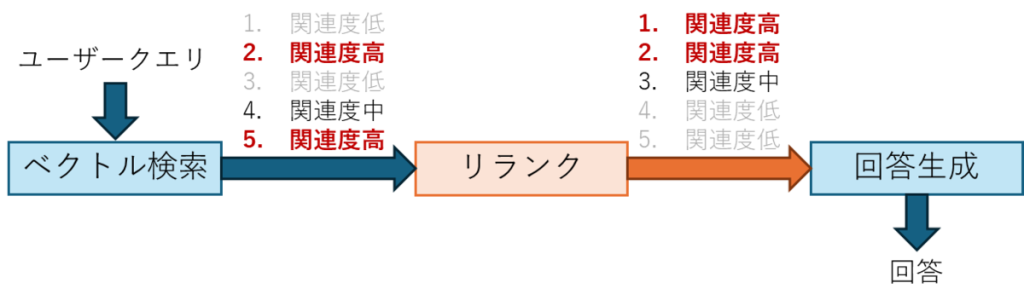
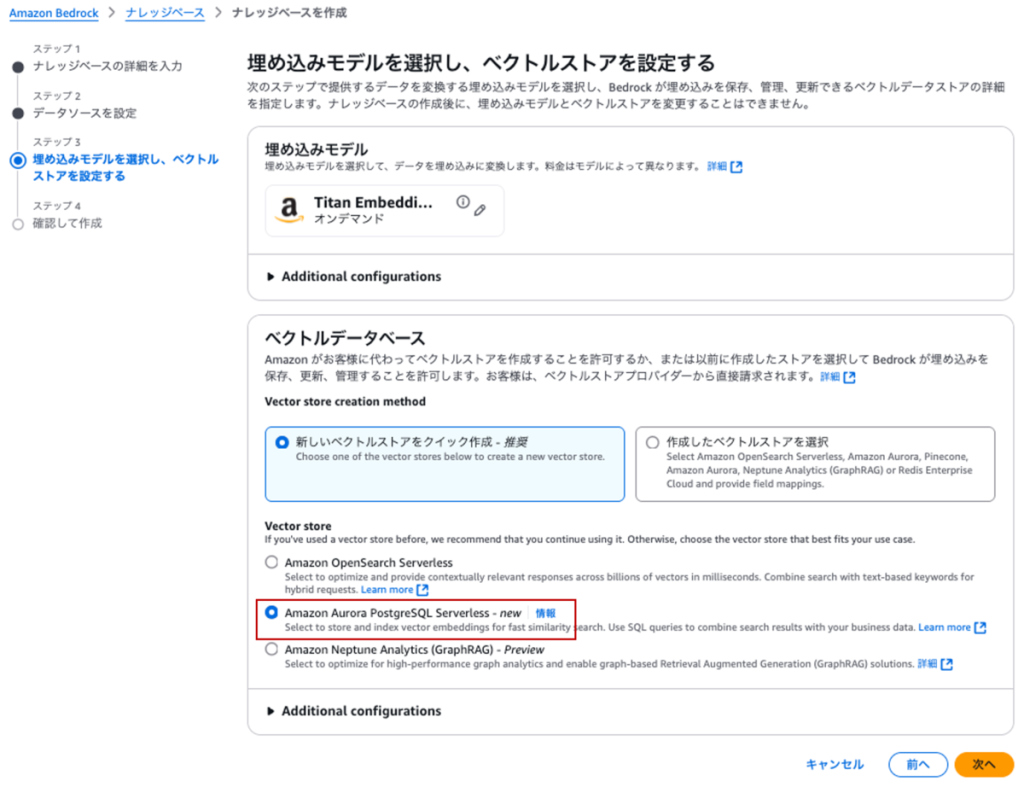
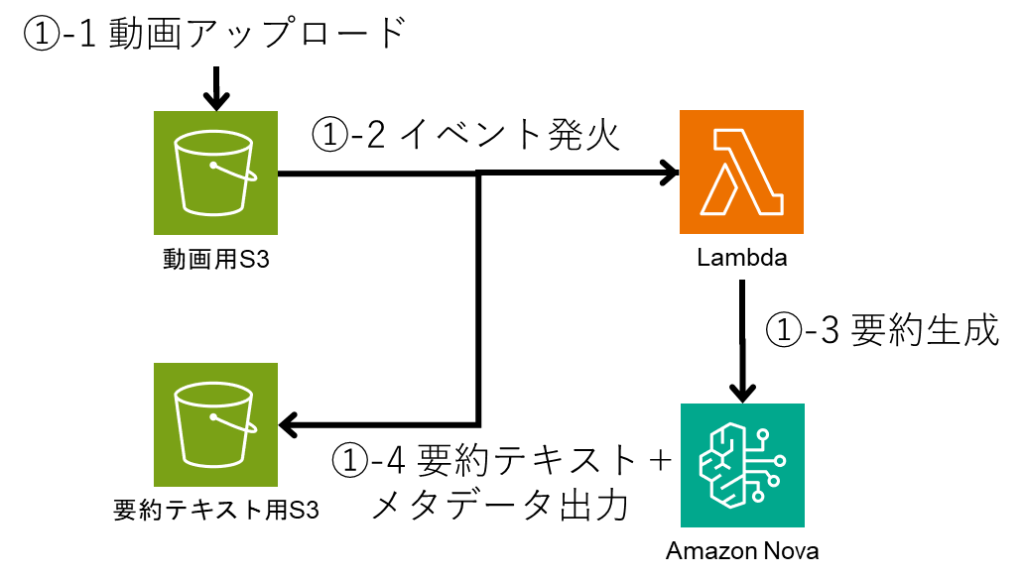
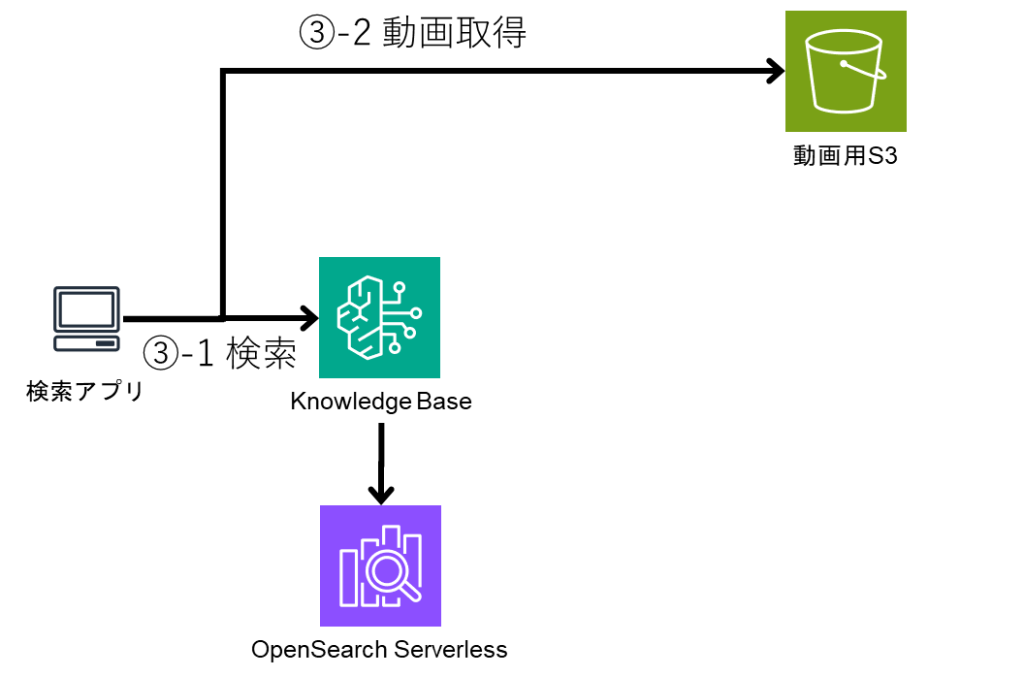
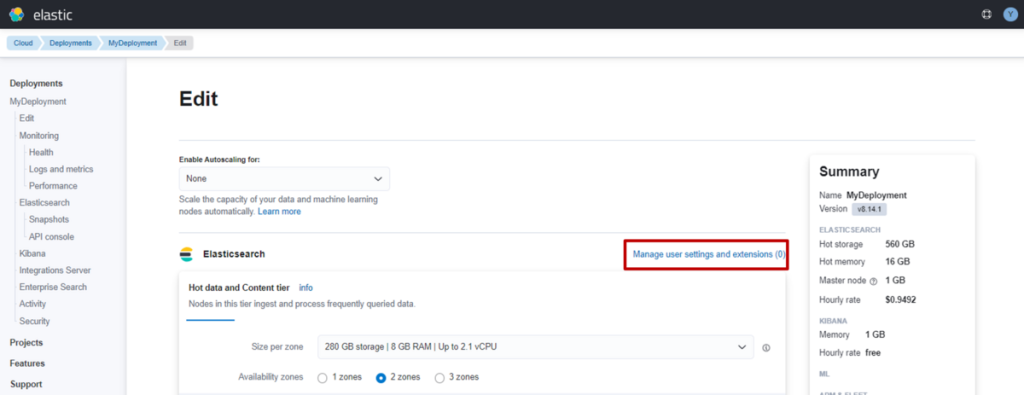
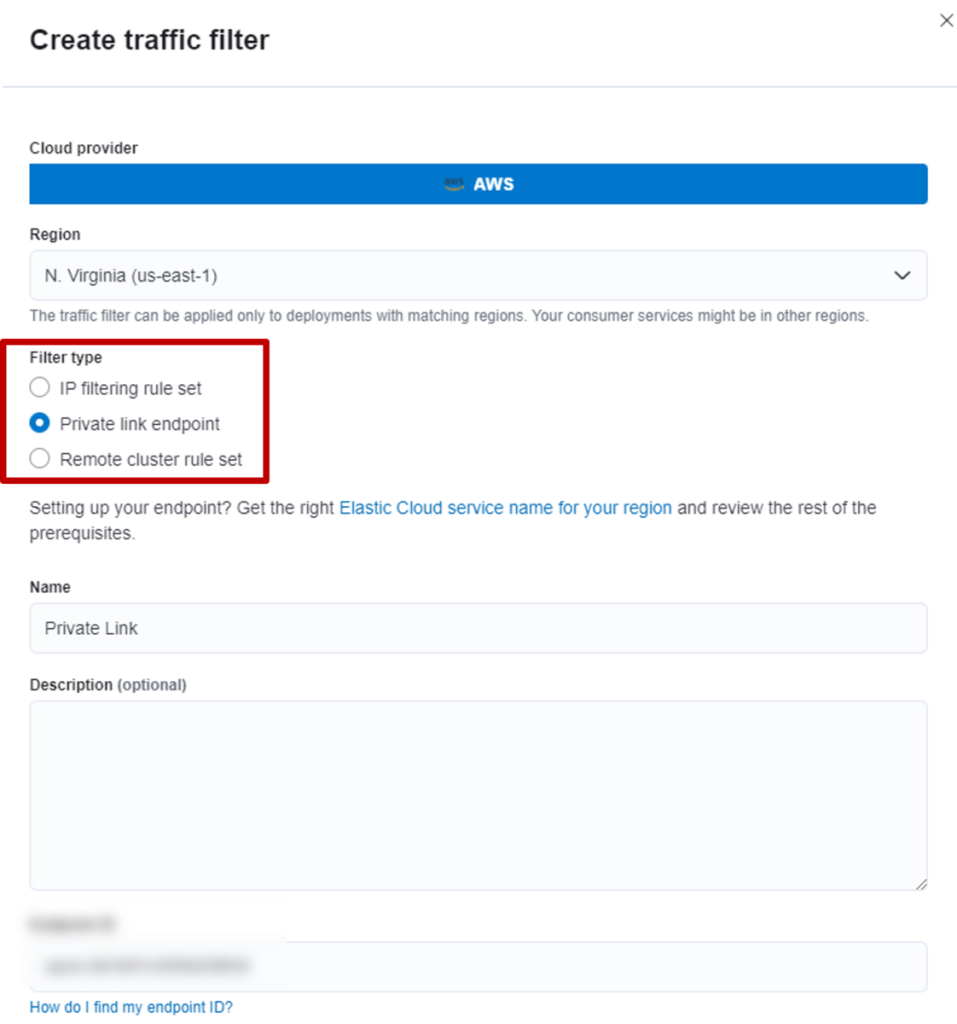
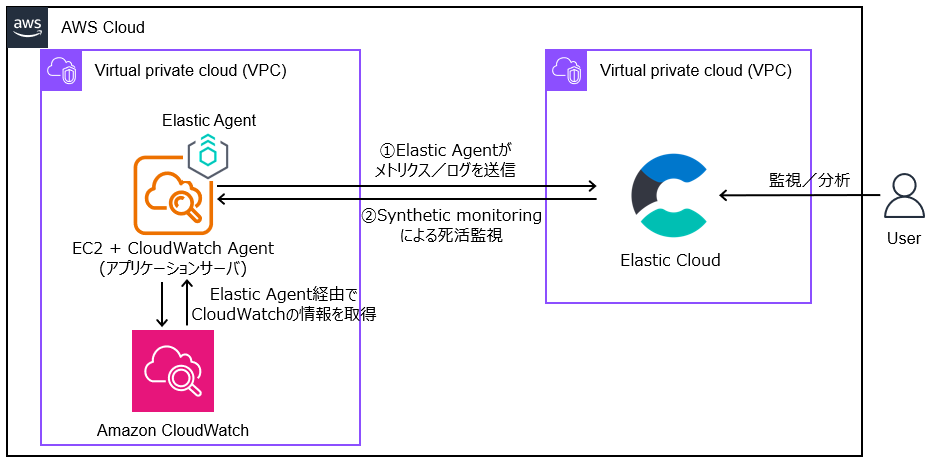
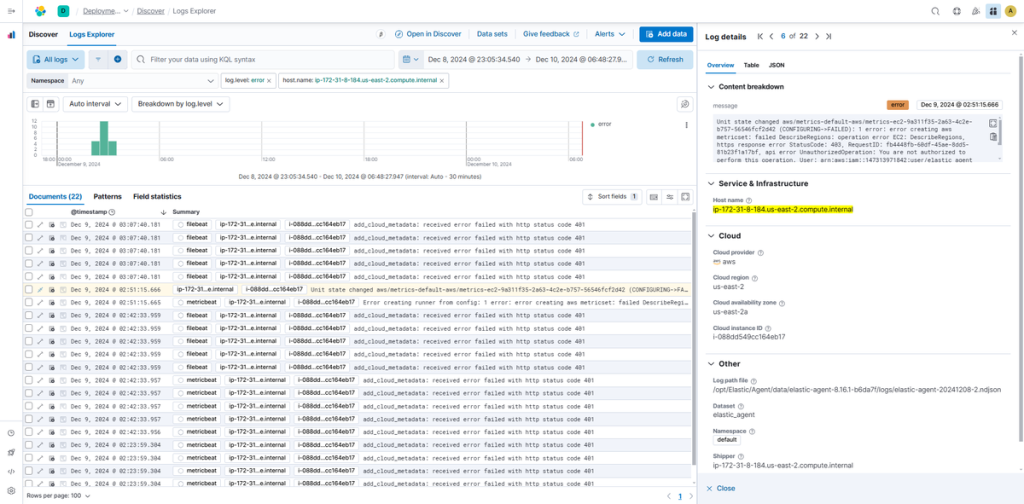
本次想为大家介绍在 2025 年纽约 AWS Summit 上发布的 S3 Vectors,内容将包含其与现有向量存储的对比分析。
相关参考链接:aws.amazon.com
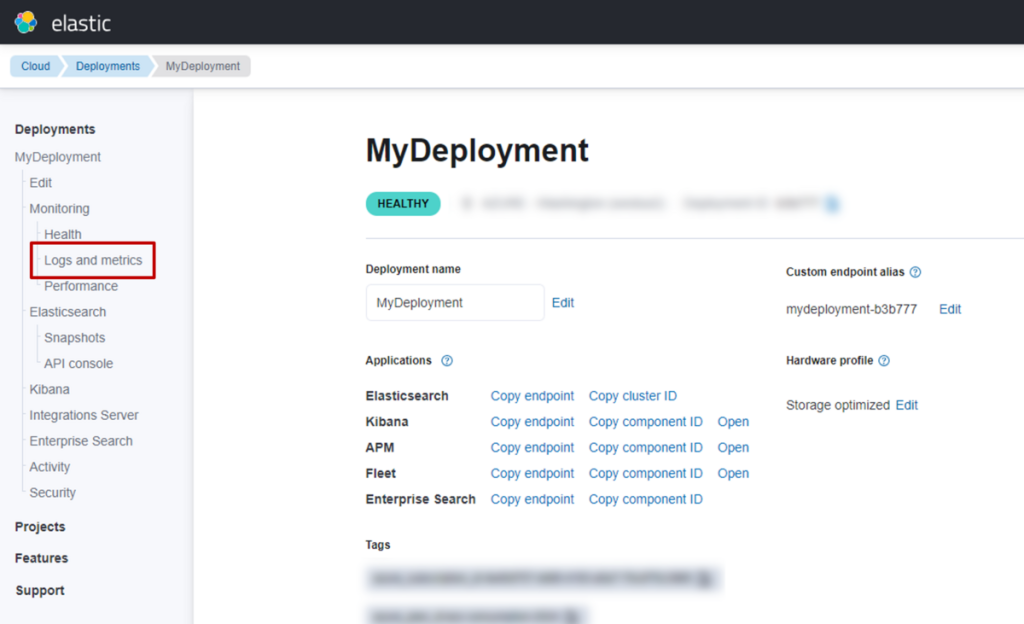
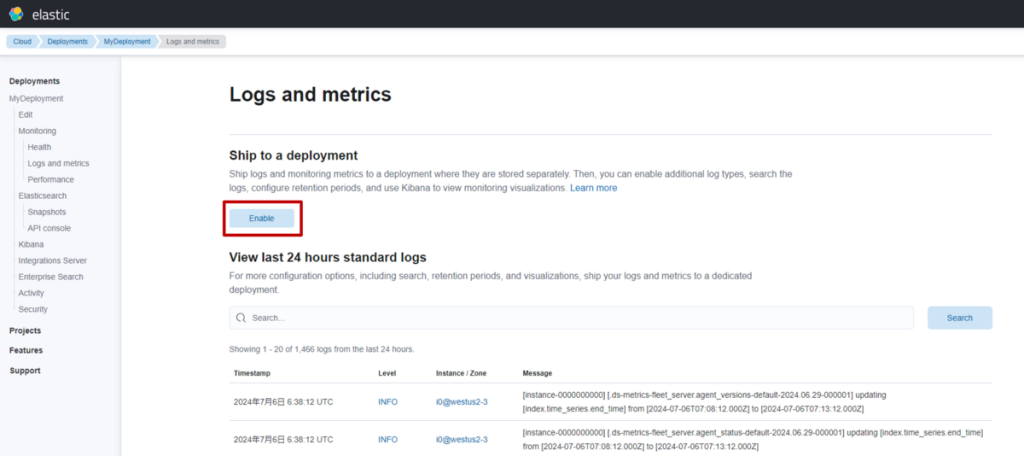
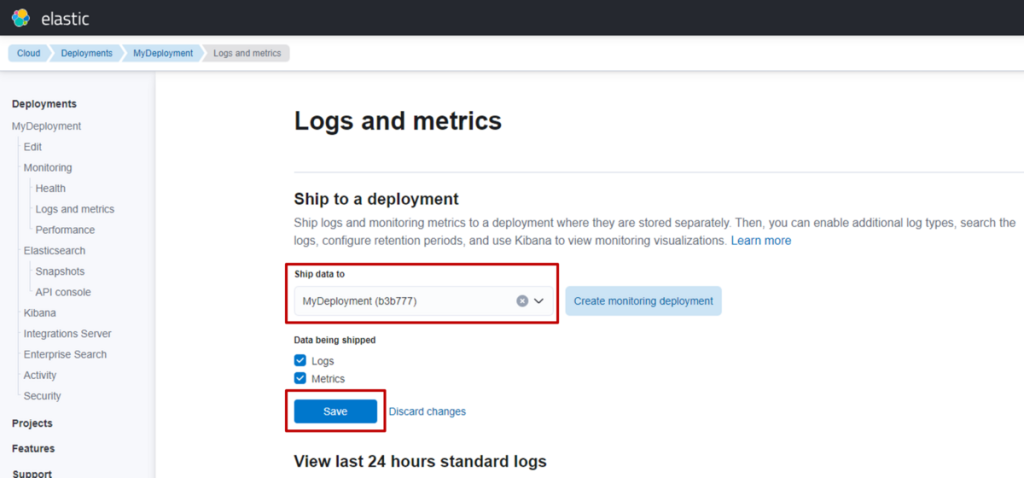
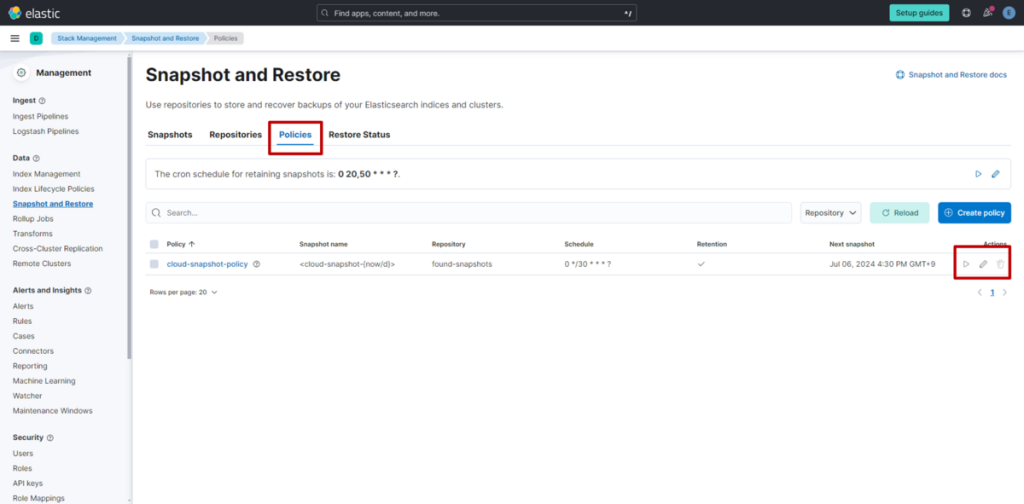
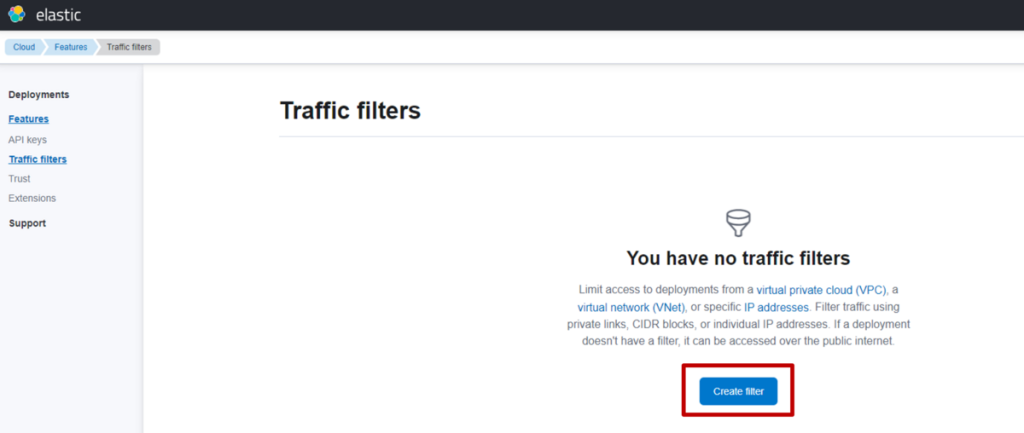
什么是 S3 Vectors
S3 Vectors 是 AWS S3 推出的新功能,本质是一款向量存储服务。由于依托 S3 提供,它与 AWS 此前可用的向量存储(如 OpenSearch Serverless、Aurora 等)不同 —— 无需承担运行成本,仅需根据数据量和 API 请求量支付费用。基于这一特性,在部分使用场景中,可实现大幅成本削减。
相关参考链接:aws.amazon.com
1. 与其他向量存储的成本对比
假设每月使用 1GB 存储容量、执行 30000 次检索,以下为 S3 Vectors 与其他向量存储的成本对比示例。※AWS 区域按美国弗吉尼亚北部计算。
| 向量存储名称 | 每月总成本 | 成本明细 |
|---|---|---|
| S3 Vectors | $2.06 | 存储:$2.00,请求:$0.06 |
| OpenSearch Serverless | $175.22 | 1 个 OCU:$175.2,存储:$0.02 |
| Aurora Serverless v2 | $87.83 | 1 个 ACU:$87.60,存储:$0.10,I/O:$0.13 |
| Pinecone | $0(入门版)/$50(标准版) | 使用 5 个及以上索引时,必须选择标准版 |
由此可见,与其他向量存储相比,S3 Vectors 的成本具有压倒性优势。
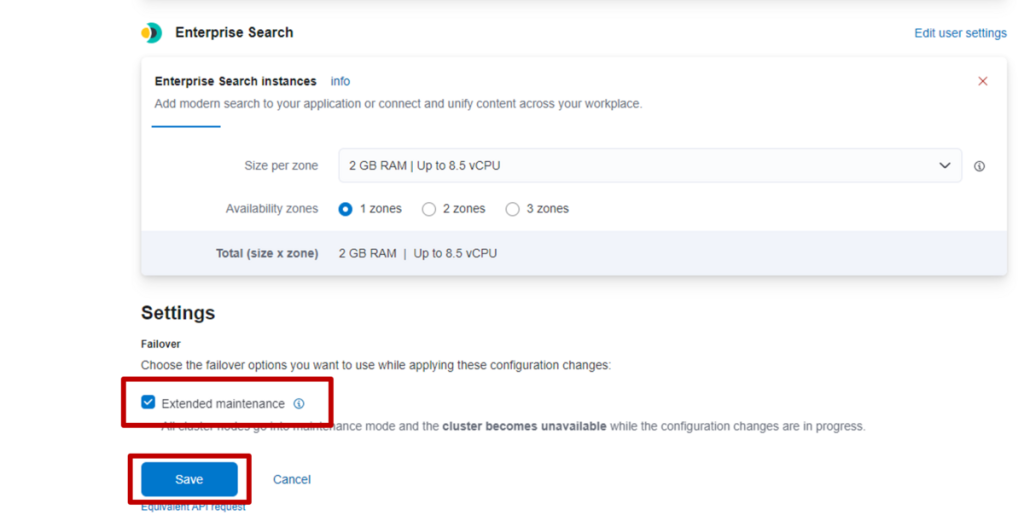
2. 功能层面的限制事项
S3 Vectors 虽能以低成本使用,但在以下功能上存在限制。
| 向量存储名称 | 元数据过滤检索功能 | 块大小(Chunk Size)限制 | 分层分块(Hierarchical Chunking) |
|---|---|---|---|
| S3 Vectors | 仅支持完全匹配检索、范围检索 | 500 tokens | △(默认设置下不可用) |
| OpenSearch Serverless | 支持部分匹配检索等灵活检索方式 | 无限制 | ○(可用) |
元数据过滤检索功能
进行元数据过滤检索时,无法像 OpenSearch Serverless 那样实现部分匹配等灵活检索,仅支持完全匹配、范围检索等基础方式。
相关参考链接:docs.aws.amazon.com
块大小限制
可创建的最大块大小限制为 500 tokens。
相关参考链接:docs.aws.amazon.com
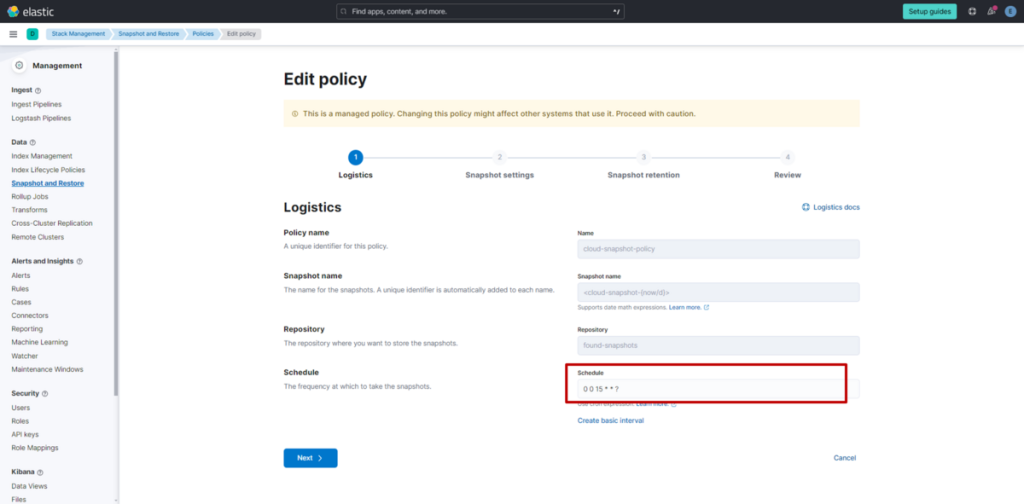
借助 Bedrock 知识库使用分层分块
在 Bedrock 知识库的默认设置下,同步时会出现以下错误,导致无法使用分层分块功能:
Filterable metadata must have at most 2048 bytes (Service: S3Vectors, Status Code: 400, Request ID:XXXXXX)
若要从 Bedrock 知识库使用分层分块,需先在 S3 Vectors 中创建以下配置的索引:
aws s3vectors create-index \
--vector-bucket-name "bucket-name" \
--index-name "index-name" \
--data-type "float32" \
--dimension 256 \
--distance-metric "cosine" \
--metadata-configuration '{"nonFilterableMetadataKeys":["AMAZON_BEDROCK_METADATA"]}'
出现该限制的原因是,分层分块的父块所存储的元数据,在默认设置下仅能容纳 2048 字节以内的内容。因此,需通过上述命令,将存储父块的元数据指定为 “不可过滤元数据”。
相关参考链接:docs.aws.amazon.com
除上述之外,由于 S3 Vectors 仅支持向量检索,因此自然无法实现 OpenSearch Serverless 等服务所支持的混合检索功能。
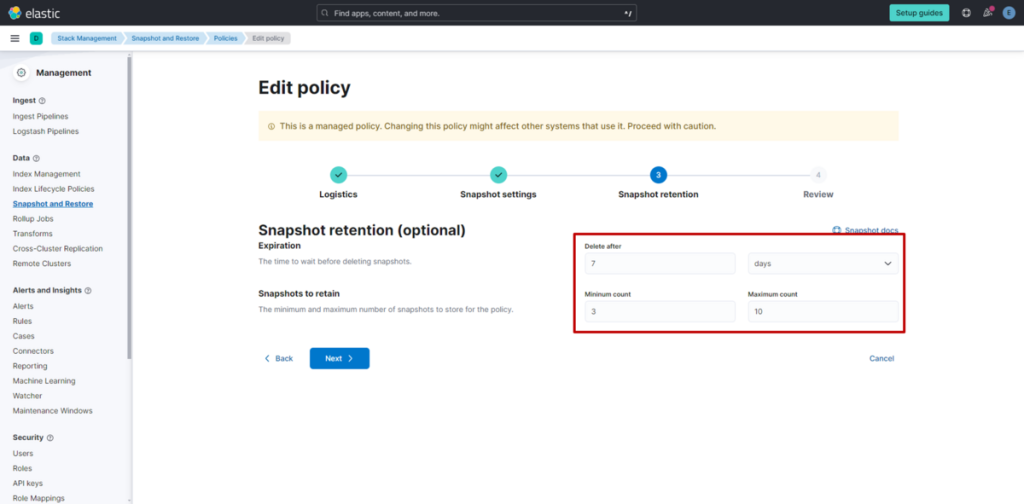
3. S3 Vectors 的最佳实践
官方文档中介绍了以下最佳实践:
| 最佳实践 | 核心要点 |
|---|---|
| 重试处理 | 为避免系统过载,推荐采用带退避策略(Backoff)的重试机制 |
| 通过索引拆分实现扩展 | 按租户或用途分别使用多个索引,可提升系统吞吐量 |
| 元数据设计 | 将仅用于参考的文本等设置为不可过滤元数据,以优化性能 |
| 访问控制 | 可通过索引级别的 IAM 权限控制,灵活设计租户级访问限制等权限管理规则 |
参考链接:docs.aws.amazon.com
其中,在访问控制方面,官方特别推荐使用 IAM 角色进行配置,这一点在实际运维中也颇具参考价值。
与其他向量存储的速度对比
接下来,我们针对实际使用中最受关注的检索速度,将 S3 Vectors 与 OpenSearch Serverless 进行对比。本次对比基于 Bedrock 知识库的检索场景,具体检索条件如下:
- 数据源:包含以下 IPA PDF 在内,共约 800MB、1000 个文件
- 《面向安全网站运营》
- 《软件开发数据白皮书 2018-2019》
- 《软件开发数据白皮书 2018-2019 金融保险业篇》
- 《软件开发数据白皮书 2018-2019 信息通信业篇》
- 嵌入模型(Embedding Model):Titan Text Embeddings v2
- 嵌入类型(Embedding Type):1024 维浮点向量嵌入
- 分块策略(Chunking Strategy):固定分块
- 分块大小(Chunk Size):300 tokens
为覆盖缓存生效的场景,我们共设计了 100 种不同的查询语句作为测试请求。
查询示例
- “制造业中新开发项目的工时与工期关系”
- “制造业改良开发中 FP(功能点)规模与工时的关系”
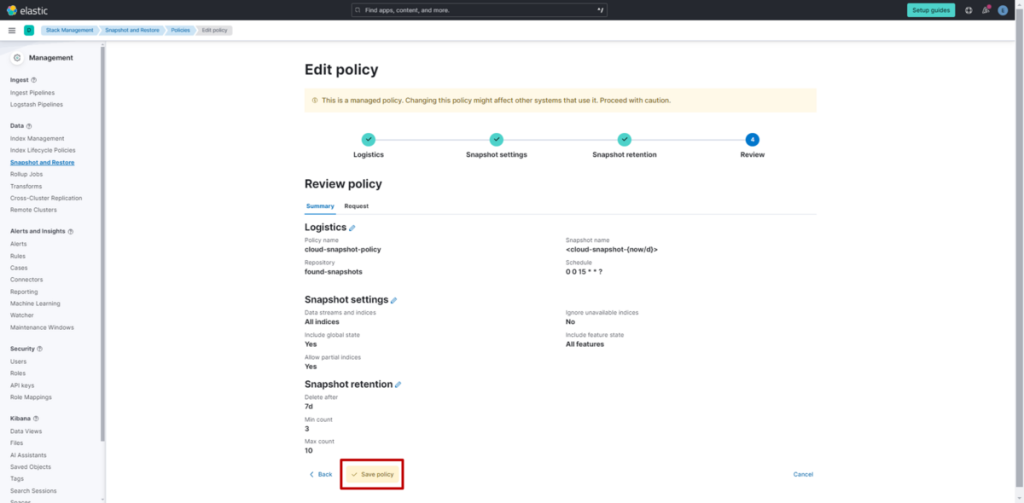
对比结果
| 向量存储名称 | 平均时间(秒) | 最大时间(秒) | 最小时间(秒) |
|---|---|---|---|
| S3 Vectors | 0.688 | 1.599 | 0.553 |
| OpenSearch Serverless | 0.433 | 0.507 | 0.383 |
结果显示,S3 Vectors 的平均检索速度比 OpenSearch Serverless 慢 0.2 秒左右,最大延迟甚至相差 1 秒。不过,结合官方文档中 “检索响应时间需控制在 1 秒以内” 的标准来看,S3 Vectors 基本能满足大多数 RAG 场景的速度要求。
参考链接:docs.aws.amazon.com
与其他向量存储的精度对比
接下来,我们从精度维度进行对比,分别测试 S3 Vectors 的 “仅向量检索” 与 OpenSearch Serverless 的 “混合检索” 效果。
本次精度验证采用 Bedrock Evaluations 工具完成。
参考链接:aws.amazon.com
1. 基于向量检索的精度对比
首先,仅针对向量检索的精度进行验证。我们沿用上述相同的知识库配置进行测试,采用以下两项指标评估精度:
- 上下文相关性:衡量检索到的文本与查询问题在上下文层面的关联程度
- 上下文覆盖率:衡量检索到的文本对正确答案全部信息的覆盖程度
对比结果
S3 Vectors 的精度

OpenSearch Serverless 的精度

由于两者采用相同的检索方式,因此精度水平基本相当。这表明,在仅使用向量检索的场景下,S3 Vectors 的精度与 OpenSearch Serverless 等现有向量存储相比并无明显差距。
2. 与混合检索的精度对比
接下来,我们使用包含产品 ID 等信息的数据集,对比 S3 Vectors 的向量检索与 OpenSearch Serverless 的混合检索精度。
本次测试采用新数据集 —— 按用户整理的 Amazon 评论数据。
混合检索验证数据集
1. 2023年亚马逊评论
https://amazon-reviews-2023.github.io
该数据集包含约 2.8 万组
product/productId: B000GKXY4S product/title: Crazy Shape Scissor Set product/price: unknown review/userId: A1QA985ULVCQOB review/profileName: Carleen M. Amadio “Lady Dragonfly” review/helpfulness: 2/2 review/score: 5.0 review/time: 1314057600 review/summary: Fun for adults too! review/text: I really enjoy these scissors for my inspiration books that I am making (like collage, but in books) and using these different textures these give is just wonderful, makes a great statement with the pictures and sayings. Want more, perfect for any need you have even for gifts as well. Pretty cool!
在精度验证时,我们准备了如下所示的 “问题 – 答案” 配对,并重点围绕混合检索的核心特征 —— 关键词检索精度展开评估。
评估用数据集示例
问题:请告知商品 ID 为 B000GKXY4S 的评论摘要。
答案:Fun for adults too!
测试时,知识库配置保持不变,仅将 OpenSearch Serverless 的检索方式指定为 “混合检索”。
精度验证结果
S3 Vectors 的精度

OpenSearch Serverless 的精度

结果显示,在 “上下文相关性” 和 “上下文覆盖率” 两项指标上,采用混合检索的 OpenSearch Serverless 精度均优于仅支持向量检索的 S3 Vectors。
以下为 “混合检索可成功匹配,但 S3 Vectors 向量检索未匹配成功” 的查询示例:
查询示例:
请告诉我商品 ID 为 B000GKXY4S 的评论摘要。
S3 Vectors(向量检索)结果:未检索到查询中包含的 ID :B000GKXY4S
返回结果为 “product/productId: B000FP553C product/title: Kinesio Scissors
OpenSearch Serverless(混合检索)结果:成功检索到查询中包含的 ID :B000GKXY4S
返回结果为 “product/productId: B000GKXY4S product/title: Crazy Shape Scissor Set
由此可见,由于 S3 Vectors 仅支持向量检索,在需指定 ID、特定单词等关键词的检索场景中,其精度会出现下降。
总结
本文结合与现有向量存储的对比,介绍了 S3 的新功能 ——S3 Vectors。尽管 S3 Vectors 在功能上存在一定限制,但对于仅需向量检索的场景,其功能已足够满足需求;加之其成本极低,非常值得尝试应用。