
不知您是否有过想要检索视频的经历?
比如,只依稀记得视频里提到过某些内容,但这些内容并未体现在视频标题中,导致无论如何都找不到对应的视频。
或许如果能像使用 Google 搜索那样检索就好了,但对于公司内部的视频或工作中使用的视频而言,事情往往没那么简单。
为了解决这类困扰,我们尝试利用 Amazon Nova 模型与 Amazon Bedrock Knowledge Base 开发了一款工具。
通过使用 Bedrock Knowledge Base,无需自行开发文档导入与检索功能,只需将视频的摘要结果存入 S3,即可轻松实现联动。
也就是说,能够在最大限度降低开发成本的同时,开发出高性能的应用程序。
1. 视频检索想要实现的目标
如果视频标题中包含目标语句,那么通过标题就能进行检索,但对于仅在视频部分内容中提及的信息等,很难通过字符串进行检索。
此外,有时用户并非对某一特定视频感兴趣,而是希望广泛检索主题相同的视频。
在本次视频检索项目中,为实现此类模糊检索,我们考虑通过 Bedrock Knowledge Base 进行向量检索。
2. 实现方法
大致步骤如下:
- 使 Amazon Nova 模型可对视频进行摘要处理
- 使摘要结果可导入 Bedrock Knowledge Base
- 实现视频检索处理
- 制作检索界面
下面分别进行详细说明。
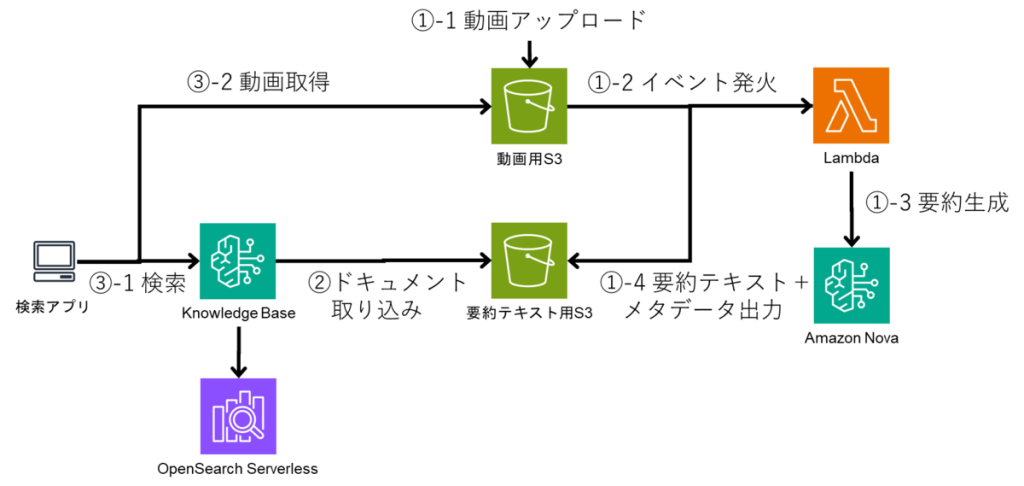
2.1. 使 Amazon Nova 模型可对视频进行摘要处理
Amazon Nova 模型除了可接收文本、图像输入外,还能接收视频输入。
我们将视频及其文字稿与下述提示词一同输入模型,让模型生成摘要文本。
本次我们从 YouTube 频道视频中,选取了时长 1 分钟以内的视频,并上传至 S3。
视频上传至 S3 后,Lambda 会接收事件触发,调用 Amazon Nova Lite 为这些视频生成说明文本,并将文本文件上传至 S3。
该文本文件随后将成为 Knowledge Base 的导入对象。
system_prompt = [
{
"text": dedent("""\
您的任务是分析给定的视频,并说明视频中呈现的内容。
视频的文字稿结果已记载在「文字稿:xxx」部分,请将其作为说明的依据。
您的回复必须严格仅由视频的说明文本构成。
请尽可能详细地进行说明。
摘要请以中文呈现。
""")
}
]
use_messages = [
{
"role": "user",
"content": [
{"text": f"视频名: {filename}"},
{
"video": {
"format": "mp4",
"source": {"bytes": b64_content},
},
},
{"text": f"文字稿: {transcript}"},
{"text": "请用中文说明此视频。"},
],
}
]
config = {"temperature": 0}
body = {
"schemaVersion": "messages-v1",
"system": system_prompt,
"messages": use_messages,
"inferenceConfig": config,
}
response = bedrock_agent.invoke_model(
modelId=MODEL_ID,
body=json.dumps(body),
contentType="application/json",
)
model_response = json.loads(response["body"].read())
content = model_response["output"]["message"]["content"][0]["text"]
模型会返回如下响应:
该视频介绍了远程办公中的 IT 工程师想吃的豆沙包排名。
首先,第 4 名是 “豆沙包 2元”,其特点是经典的松软面团搭配口感顺滑的红豆沙,甜度适中。第 3 名是 “满满奶油一口包 3 元”,内部塞满了奶油,食用时的满足感很强。第 2 名是 “高级网购款 5 元”,表面撒有芝麻,有着类似馒头般的雅致口感且质地厚实。第 1 名是 “薄皮方形包 10 元”,是方便食用的两口大小,红豆馅密度高,且不会弄脏手。
此外,由于本次仅针对短时长视频,因此采用了直接向 API 提交视频的方式,但如果文件体积较大,则需要采取诸如读取上传至 S3 的文件、将视频分段传输后再合并等方法。
2.2. 使摘要结果可导入 Bedrock Knowledge Base

接下来需要通过 Knowledge Base 进行同步,以导入上述说明文本。但如果直接导入,无法实现原始视频与上传的文本文件之间的关联。
为解决这一问题,我们使用了 Knowledge Base 的 metadata.json 功能。
在此 JSON 文件中记载的内容,会在 Knowledge Base 同步时作为元数据保存到 OpenSearch Serverless 中,可供检索时获取。
本次我们在元数据中指定了视频的 URL,用于检索后的界面显示。
{
"metadataAttributes": {
"original_path": "s3://bucket/path/to/video.mp4"
}
}
当视频的说明文本与对应的 metadata.json 配置完成后,即可对 Knowledge Base 进行同步。
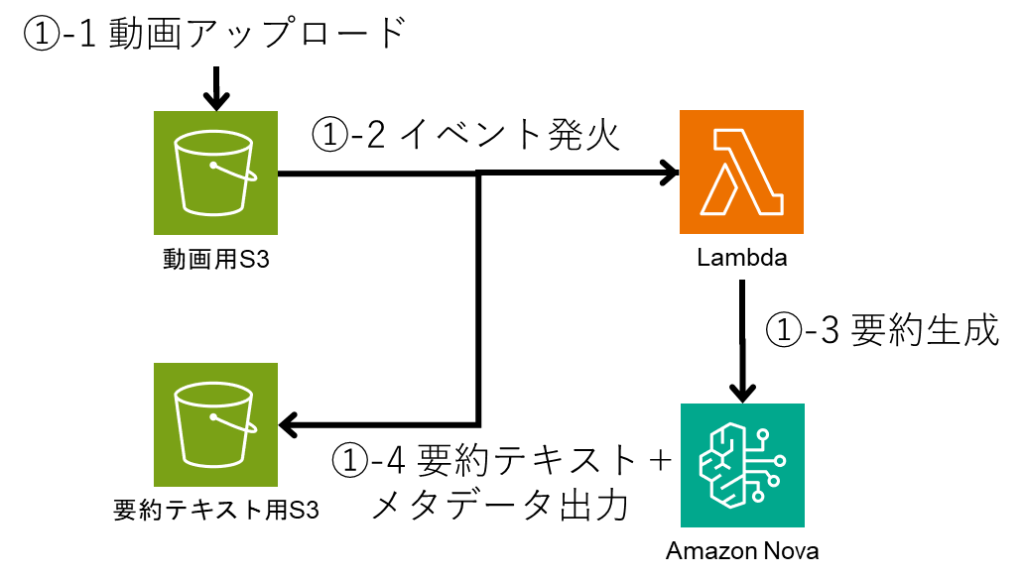
2.3. 实现视频检索处理
检索时使用了 Knowledge Base 的 Retrieve API。
此外,通过在检索后设置分数下限作为阈值,可确保经重排序后被判定为相关性较低的视频不纳入检索结果。
const input = {
knowledgeBaseId,
retrievalQuery: {
text: query.trim(),
}
retrievalConfiguration: {
vectorSearchConfiguration: {
numberOfResults: 20,
overrideSearchType: "HYBRID",
rerankingConfiguration: {
bedrockRerankingConfiguration: {
modelConfiguration: {
modelArn: AMAZON_RERANK_MODEL,
},
numberOfRerankedResults: 10,
},
type: "BEDROCK_RERANKING_MODEL",
},
},
},
};
const command = new RetrieveCommand(input);
return client.send(command);
可按如下方式获取视频的概要及视频文件路径:
{
"retrievalResults": [{
"content": {
"text": "该视频介绍了远程办公中的 IT 工程师想吃的豆沙包排名……",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://bucket/path/to/summary.txt"
},
"type": "S3"
},
"metadata": {
"original_path": "s3://bucket/path/to/video.mp4"
}
}]
}
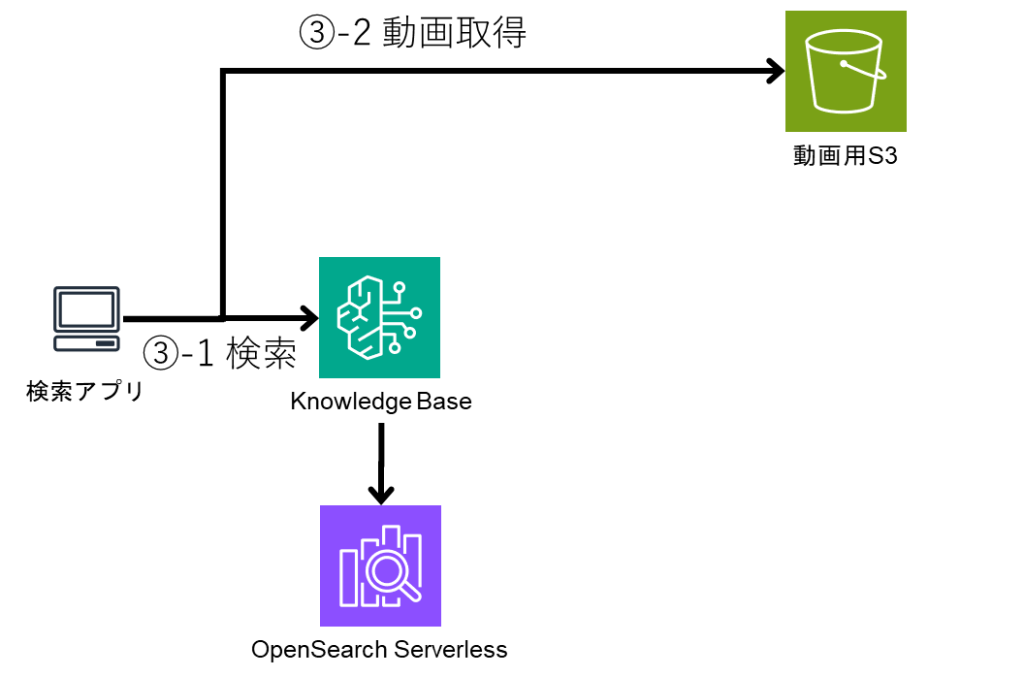
2.4. 制作检索界面
本次使用 bolt.new 制作了执行上述检索的界面。
虽然我不太擅长前端开发,但只需用中文下达指令,就能制作出非常不错的应用,这一点让我很惊喜。
3. 结果
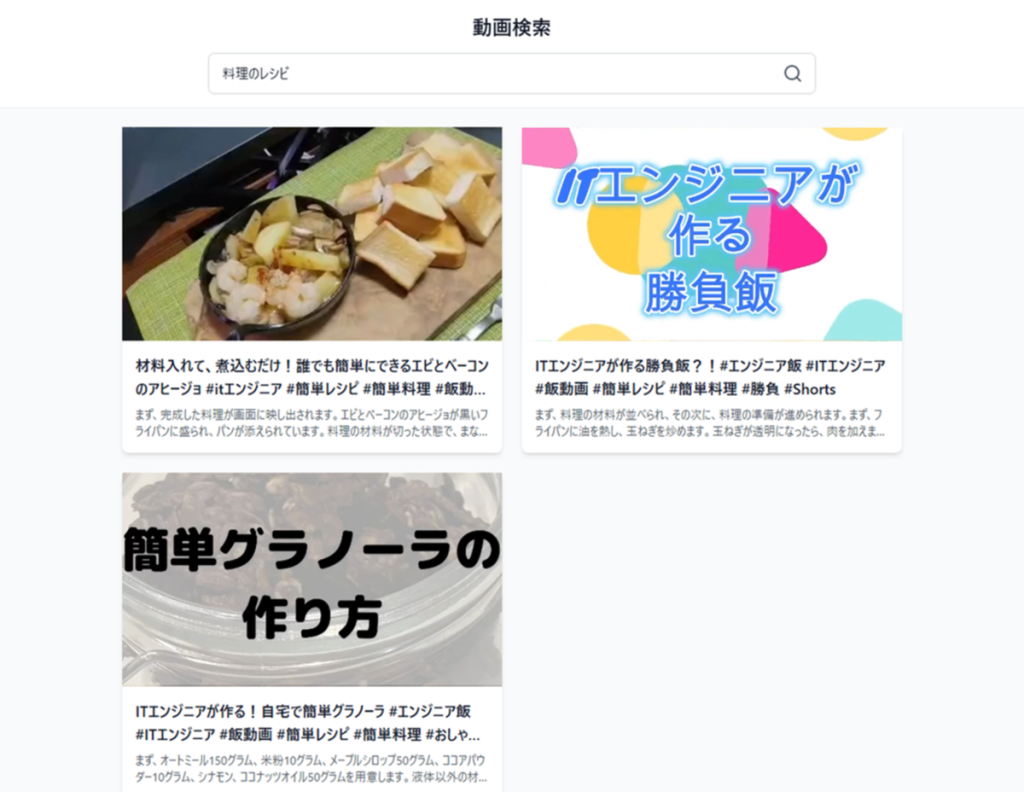
3.1. 尝试用视频中包含的语句进行检索
首先,我们尝试使用既包含在视频标题中、也包含在生成式 AI 生成的摘要文本中的关键词进行检索。
经确认,目标视频会显示在检索结果的第一位。
当遇到 “想再看那个视频,但用传统检索方式搜不到” 的情况时,使用这款应用就能立即找到想看的视频。
“美味的豆沙包”
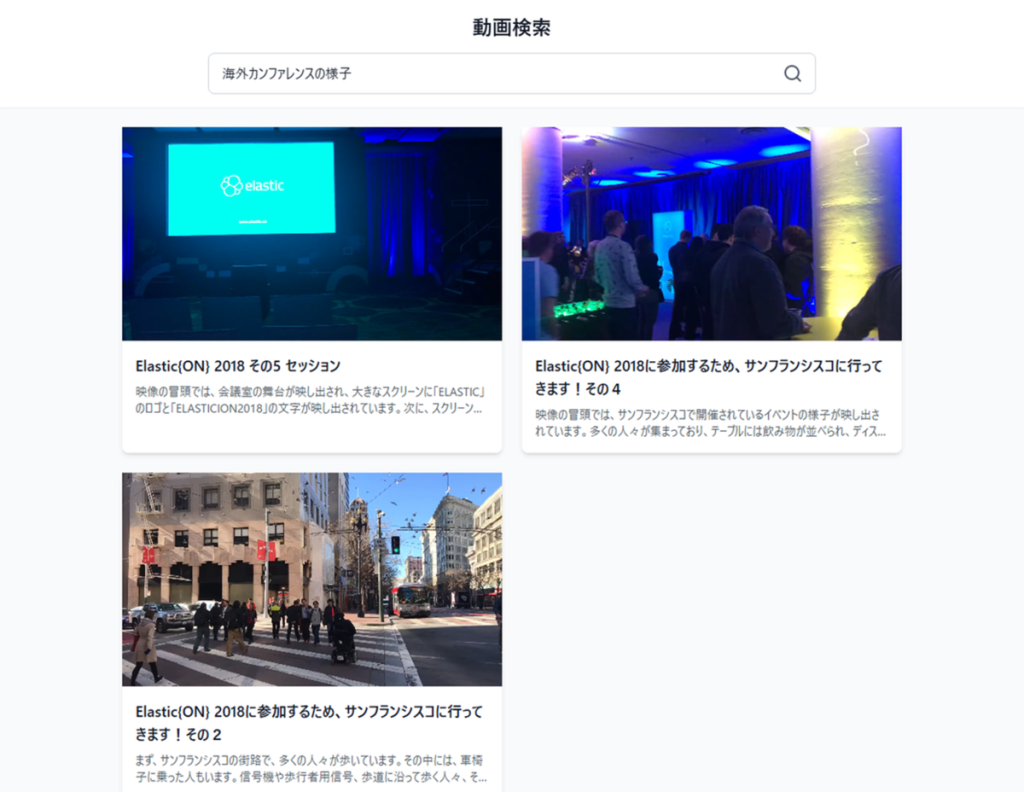
3.2. 尝试用视频中不包含的语句进行检索
接下来,我们尝试用未出现在标题和摘要文本中,但凭借向量检索可能捕捉到相关内容的语句进行了检索。
此次检索也成功命中了一段视频,内容是 2018 年参加在美国旧金山举办的 “Elastic {ON}” 大会时的场景。
虽然本次知识库中仅导入了 Elastic {ON} 相关的视频,但如果预先导入其他海外大会的视频,就能实现 “并非想找某一特定视频,而是希望广泛获取同类视频” 的需求。
总结
目前,Bedrock Knowledge Base 尚无法直接输入视频,但通过使用 Amazon Nova 生成视频说明文本,我们间接实现了视频检索功能。
虽然通过自行对视频进行嵌入处理也能实现相同功能,但 Bedrock Knowledge Base 的优势在于可轻松集成内容导入与检索能力。
内容导入仅需将文件放入 S3 并执行 “同步” 操作即可,检索也只需调用 Retrieve API。借助 Retrieve API,还能通过重排序功能轻松优化检索结果。