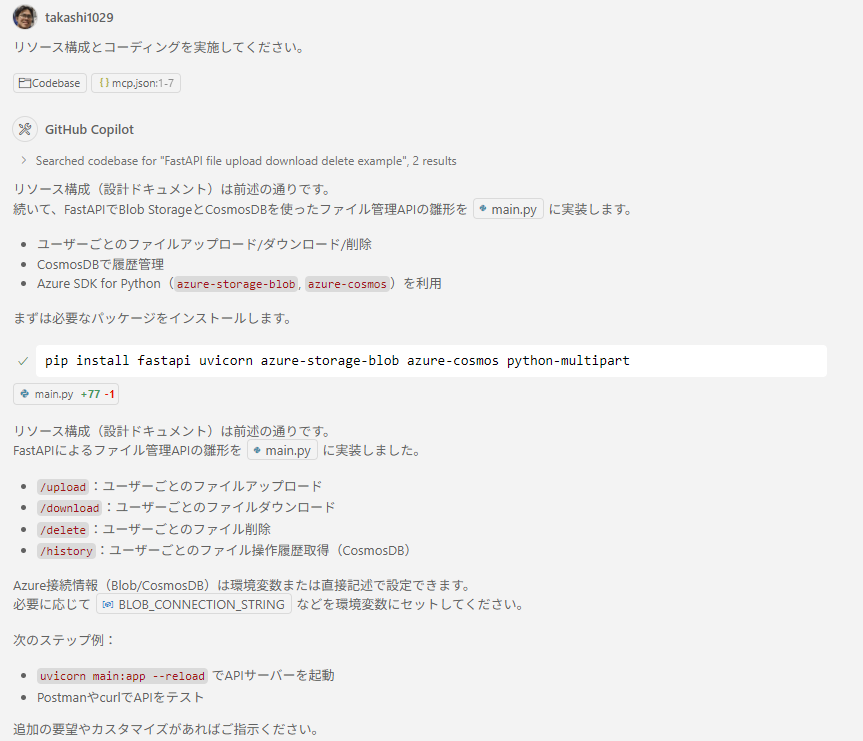
前言
今天我要对可作为 Amazon Bedrock Knowledge Bases 向量数据库(搜索引擎)的工具进行对比。
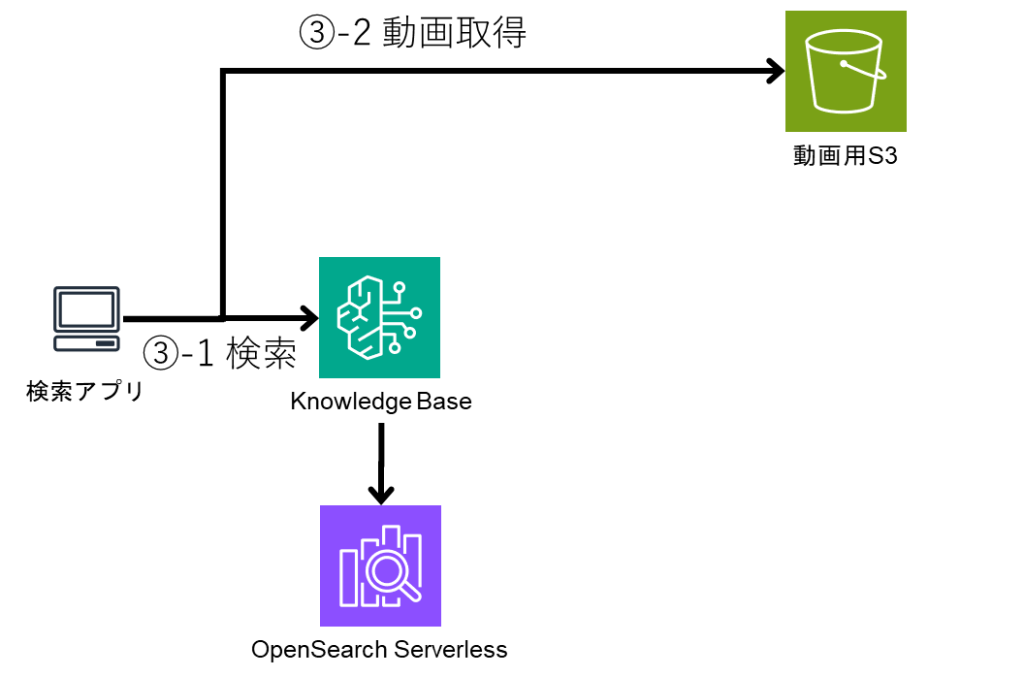
目前,Bedrock Knowledge Base 中支持混合搜索的向量数据库如下:
- OpenSearch Serverless
- OpenSearch Managed Cluster(OpenSearch 托管集群)
- Aurora Serverless V2(PostgreSQL)
- MongoDB Atlas
本次,我将针对其中使用率较高的OpenSearch Serverless与Aurora Serverless V2(PostgreSQL) ,对比二者在混合搜索中的精度表现。
概述
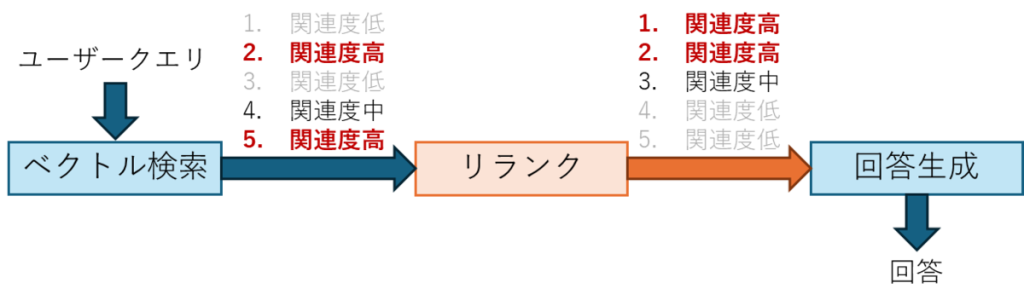
混合搜索是一种结合向量(语义)搜索与关键词(全文)搜索来查找相关文档的搜索方式。这种方式既能通过向量搜索实现基于语义的检索,又能通过关键词搜索,在检索过程中纳入指定关键词的考量。
OpenSearch Serverless 与 Aurora Serverless V2(PostgreSQL)的对比
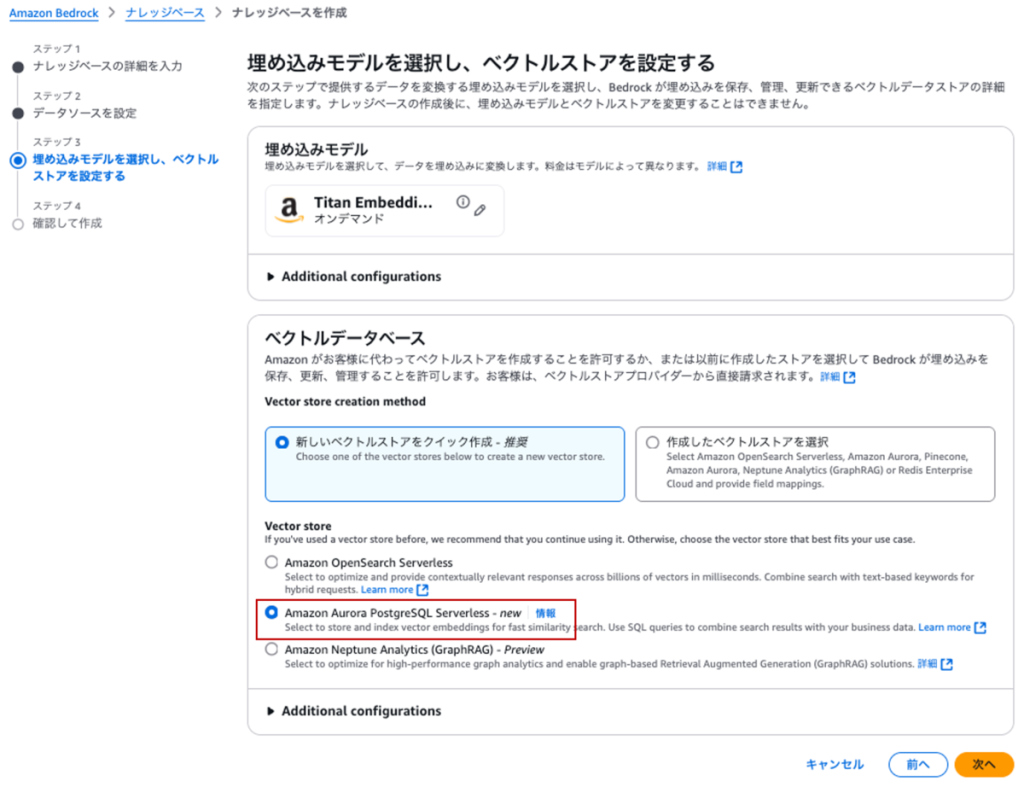
下面我将对本次作为数据存储使用的 OpenSearch Serverless 和 Aurora Serverless V2(PostgreSQL)进行简单对比。
| 对比维度 | OpenSearch Serverless | Aurora Serverless V2(PostgreSQL) |
|---|---|---|
| 混合搜索(Bedrock Knowledge Bases) | 支持 | 支持 |
| 中文支持 | 可使用 Kuromoji 等中文形态素分析 | PostgreSQL 标准全文搜索(目前不支持中文形态素分析) |
| 向量存储格式 | 支持浮点数 / 二进制两种格式 | 浮点数(基于 pgvector 插件) |
| 计费单位 | OCU / 小时(最小 1 个 OCU,含 0.5 计算 OCU+0.5 存储 OCU) | ACU / 小时(最小 0.5 个 ACU) |
| 最小配置计费示例 | 175.22 美元(1 个 OCU:175.2 美元,存储:0.02 美元) | 87.83 美元(1 个 ACU:87.60 美元,I/O:0.13 美元) |
(参考链接:aws.amazon.com;aws.amazon.com)
OpenSearch Serverless 支持中文形态素分析,因此即便使用中文,也能高精度地进行关键词搜索。另一方面,Aurora Serverless V2(PostgreSQL)在最小配置下的费用更具优势,但由于其默认不支持中文形态素分析,因此在中文混合搜索的精度方面存在不确定性。
精度对比实验
为对比 OpenSearch Serverless 与 Aurora Serverless V2(PostgreSQL)的精度,本次将开展以下两类实验:
- 英文数据集的搜索精度对比
- 中文数据集的搜索精度对比
尤其对于中文数据集,由于 Aurora Serverless V2(PostgreSQL)不支持中文形态素分析,预计 OpenSearch Serverless 在精度上会更具优势。
1. 实验设置
以下是本次实验使用的基本设置。首先,Bedrock Knowledge Base 的基础设置如下,仅向量存储工具为两者的差异点。
| 嵌入模型(Embedding Model) | 嵌入类型(Embedding Type) | 分块策略(Chunking Strategy) |
|---|---|---|
| Titan Text Embeddings V2 | 1024 维浮点数向量嵌入 | 分层分块(父块:2000 字符,子块:500 字符,重叠:50 字符) |
精度对比将通过 Bedrock Evaluations 完成。
(参考链接:docs.aws.amazon.com)
本次对比将采用以下两项指标,指标取值范围均为 0~1,数值越大表示对问题的回答质量越高:
- Context relevance(上下文相关性):衡量获取的文本与问题在上下文层面的关联程度
- Context coverage(上下文覆盖率):衡量获取的文本对正确数据中全部信息的覆盖程度
2. 混合搜索对比(英文数据集)
1. 数据集
本次实验使用的数据集如下:Amazon Reviews 2023(2023 年亚马逊评论数据集)
(参考链接:amazon-reviews-2023.github.io)
该数据集包含约 2.8 万组 “产品 ID – 评论” 数据,示例如下:
product/productId: B000GKXY4S
product/title: Crazy Shape Scissor Set
product/price: unknown
review/userId: A1QA985ULVCQOB
review/profileName: Carleen M. Amadio "Lady Dragonfly"
review/helpfulness: 2/2
review/score: 5.0
review/time: 1314057600
review/summary: Fun for adults too!
review/text: I really enjoy these scissors for my inspiration books that I am making (like collage, but in books) and using these different textures these give is just wonderful, makes a great statement with the pictures and sayings. Want more, perfect for any need you have even for gifts as well. Pretty cool!
2. 结果(英文)
对比结果如下,
数值越高,评估结果越好。
| 指标类型 | OpenSearch无服务器 | Aurora Serverless V2(PostgreSQL) |
| 上下文相关性 | 0.06 | 0.07 |
| 上下文覆盖 | 0.19 | 0.18 |
3. 混合搜索对比(中文数据集)
那么,接下来将对核心中文数据集的(检索)精度展开比较分析。
1. OpenSearch(中文分词设置示例)
由于 OpenSearch Serverless 可使用 Kuromoji 形态素分析(中文分词工具),因此需进行相关配置。
通过该配置,中文文本能被正确分割,进而有望提升关键词搜索的精度。
配置示例
PUT bedrock-knowledge-base-hybrid-index
{
"mappings": {
"properties": {
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": false
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text",
"analyzer": "custom_kuromoji_analyzer"
},
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"engine": "faiss",
"space_type": "cosinesimil"
}
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"knn.algo_param": {
"ef_search": "512"
},
"knn": "true",
"analysis": {
"analyzer": {
"custom_kuromoji_analyzer": {
"tokenizer": "kuromoji_tokenizer",
"filter": [
"kuromoji_baseform",
"ja_stop"
],
"char_filter": [
"icu_normalizer"
]
}
}
}
}
}
}
2. 插入的中文文档
本次使用的数据集,是让 ChatGPT 输出的,具体如下。
在混合检索时,我们期望能以 “张居正生平” 作为关键词,检索到相关信息。
张居正像(现藏于中国国家博物馆)
时代 明朝中后期(嘉靖、隆庆、万历年间)
生诞 嘉靖四年五月初三日(1525 年 5 月 24 日)
死没 万历十年六月二十日(1582 年 7 月 9 日)(58 岁卒)
改名 无(一直以 “张居正” 为名,字叔大,号太岳)
字:叔大
号:太岳
谥号:文忠(万历朝初赠,后被追夺,天启朝恢复)
墓所:湖北省荆州市沙市区张居正墓
官职:吏部左侍郎兼东阁大学士、礼部尚书兼武英殿大学士、少师兼太子太师、吏部尚书、中极殿大学士(内阁首辅)
主要事迹 1. 推行 “一条鞭法”,将田赋、徭役和杂税合并,按田亩折算银两征收,简化税制,增加财政收入;2. 实施 “考成法”,考核各级官吏政绩,整顿吏治,提高行政效率;3. 重用戚继光、李成梁等将领,加强北方边防,抵御蒙古部落侵扰,稳定边疆局势;4. 主持治理黄河、淮河,任用潘季驯负责河工,疏通河道,减少水患,保障农业生产。
评估用数据集示例
- 问题:请告知张居正被任命为吏部尚书的年份
- 答案:张居正于明万历元年(公元 1573 年) 正式被任命为吏部尚书。
3. 结果(中文)
以下是中文数据集的精度对比结果。数值越大,代表评价结果越好。
| Metric type | OpenSearch Serverless | Aurora Serverless V2(PostgreSQL) |
|---|---|---|
| Context relevance | 0.45 | 0.43 |
| Context coverage | 1.00 | 0.93 |
如上表所示,尽管优势微弱,但 OpenSearch Serverless 在两项指标上均超过 Aurora Serverless V2(PostgreSQL)。尤其在衡量 “问题回答覆盖度” 的上下文覆盖率(Context coverage)指标上,OpenSearch Serverless 的优势更为明显。
我们认为,这一差异源于 OpenSearch Serverless 通过 Kuromoji 实现了中文形态素分析支持,进而在混合搜索的关键词搜索精度上形成了优势。
此外,我们也对比了两者的搜索速度,结果如下:我们连续执行 5 种不同查询,去除最大值与最小值后计算 “截尾平均值”(Trimmed Mean)进行对比。
| OpenSearch Serverless(秒) | Aurora Serverless V2(PostgreSQL)(秒) |
|---|---|
| 0.48 秒 | 0.55 秒 |
从搜索速度来看,OpenSearch Serverless 同样具备更快的检索表现。
总结
本次实验对比了在 Bedrock 知识库中,分别使用 OpenSearch Serverless 与 Aurora Serverless V2(PostgreSQL)实现混合搜索的效果。结果显示,在中文搜索的精度与速度上,OpenSearch Serverless 均优于 Aurora Serverless V2(PostgreSQL)。
需要说明的是,本次验证基于 “数据量较少” 的场景,因此两者的差距并不显著;若后续数据量增加,结果可能会发生变化。不过,从整体来看,两款工具在精度与速度上均具备较高性能,建议根据实际使用场景与数据量选择合适的工具。