前言
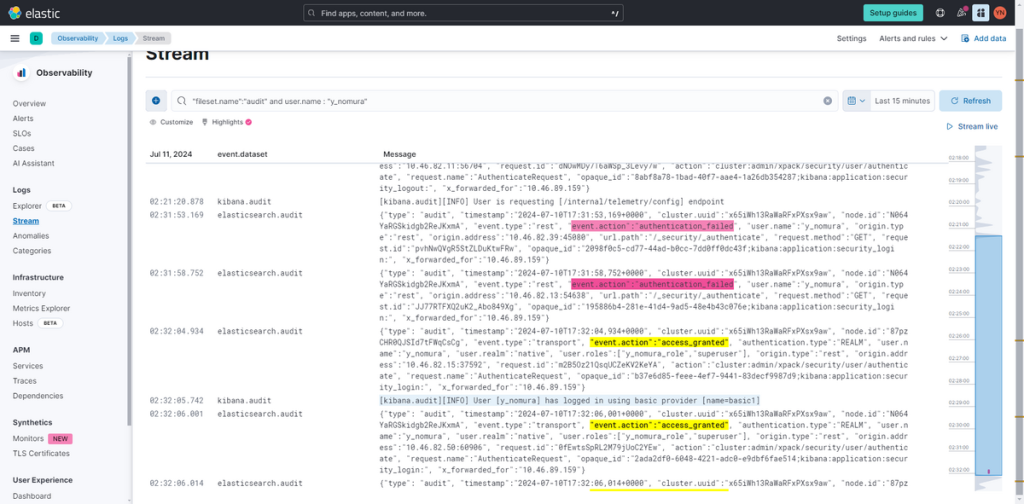
近年来,在检索增强生成(RAG,Retrieval-Augmented Generation)兴起等背景下,向量搜索的重要性日益凸显。向量搜索是将文本、图像等高维数据嵌入向量空间,基于相似度进行检索的技术。通过该技术,能够实现传统关键词搜索无法捕捉的、基于语义相似性的检索。
另一方面,可处理向量搜索的产品与服务不断增多,想必有不少人在选择时会感到迷茫。不同服务支持的向量搜索选项也存在差异。尤其在近期,为提升向量搜索性能与资源效率的各类选项纷纷涌现,其中 “向量量化” 与 “二进制向量” 作为有助于降低资源用量、提升检索速度的技术备受关注。
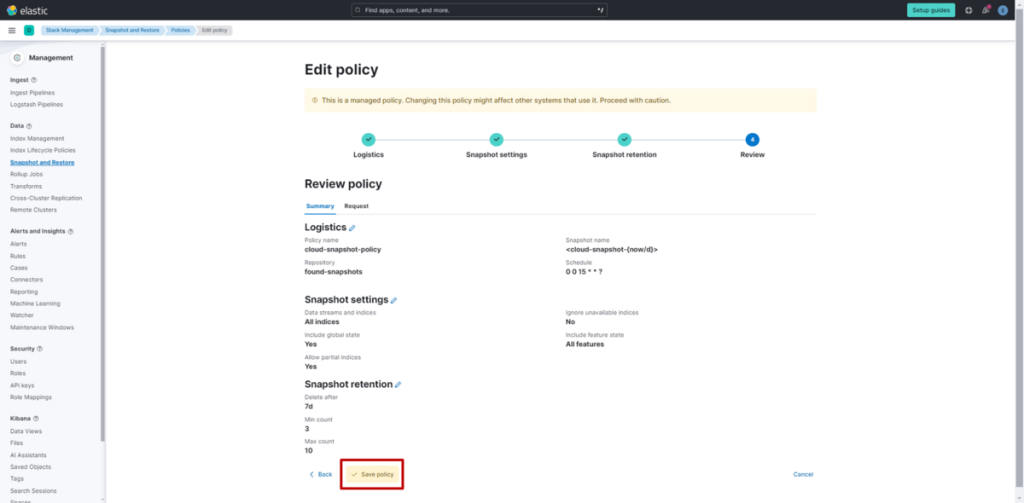
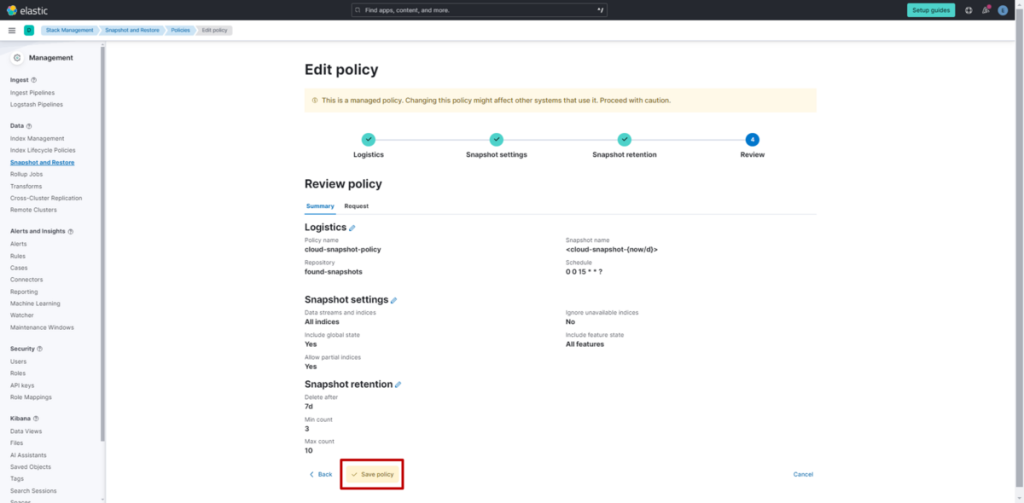
本文将聚焦向量搜索引擎的有力选择之一 ——Elasticsearch,结合具体配置方法,解析向量量化、二进制向量等选项及其效果。
Elasticsearch 中的向量搜索
Elasticsearch 作为全文搜索引擎广为人知,而自 7.x 版本起,它开始支持稠密向量(Dense Vector)类型,向量搜索功能得到强化。稠密向量是用于存储高维向量数据的数据类型。
Elasticsearch 稠密向量文档:Elasticsearch Dense Vector 文档
向量搜索的算法
在 Elasticsearch 中处理稠密向量时,会使用近似最近邻(ANN)搜索算法。目前可使用名为 HNSW 的算法。HNSW(Hierarchical Navigable Small World,分层可导航小世界)是一种高速的近似最近邻搜索算法,采用基于图的数据结构,能高效检索相似向量。
用于资源削减的选项:向量量化与二进制向量
向量搜索的性能与资源效率存在权衡关系。Elasticsearch 提供向量量化与二进制向量作为调节这种权衡的选项。
| 选项 | 说明 | 优势 | 劣势 | 推荐使用场景 |
|---|---|---|---|---|
| 向量量化 | 将向量各维度用更少的比特数表示的方法。在 Elasticsearch 中,可替代 32 比特的 float 型,实现 8 比特、4 比特、1 比特的量化。 | 大幅降低存储大小与内存用量,还有可能提升查询性能。 | 可能导致精度下降。 | 需降低存储成本与内存用量,追求一定精度与性能平衡的场景。 |
| 二进制向量 | 将向量各维度用 0 或 1 表示的方法。可使用汉明距离等进行高速的相似度计算。 | 大幅减少计算时间及磁盘、内存用量,支持针对二进制向量的高速距离计算(如汉明距离)。 | 与使用 float 型相比精度下降,且需要用于生成二进制向量的专用嵌入(Embedding)模型。 | 可牺牲部分精度以大幅控制存储与内存用量,或需高速检索的场景。 |
二进制向量详情
二进制向量(比特向量)是一种蕴藏着大幅提升向量搜索效率潜力的技术。
机制
二进制向量是基于阈值将原始向量(通常为浮点数向量)的各维度转换为 0 或 1 得到的。
距离计算
二进制向量间的相似度计算采用汉明距离(比特位不同的位置数量),其速度远快于浮点数向量间的余弦相似度或欧几里得距离计算。
生成方法
- 专用嵌入模型:使用可直接输出二进制向量的嵌入模型。
- 现有嵌入模型 + 二值化:对通过现有嵌入模型得到的浮点数向量,采用阈值处理等方式进行二值化。
量化 / 二值化的优势与注意事项
向量量化与二值化是提升稠密向量存储效率与查询性能的有力手段,但在引入时需理解以下优势与注意事项。
优势:
- 降低存储成本:可大幅减小索引大小,降低磁盘存储成本。
- 减少内存用量:向量数据更易存入内存,从而减少内存用量,提升 Elasticsearch 集群的稳定性。
- 提升查询性能:对量化 / 二值化后的向量进行运算速度更快,有望提升查询性能。
注意事项:
- 精度的权衡:量化 / 二值化通常与精度存在权衡关系,数据压缩程度越高,检索精度下降的可能性越大。
- 选择合适的方法:需结合业务需求允许的精度损失与存储效率的平衡,选择合适的量化级别或二进制向量化方法。
基于 JMTEB 数据的测试
存在名为 JMTEB(Japanese Massive Text Embedding Benchmark,日语大规模文本嵌入基准)的嵌入精度评估基准。
JMTEB 通过 5 个使用各类日语开放数据的任务对嵌入模型进行评估。本次将利用部分数据集,观察修改量化选项后对磁盘用量及精度的影响程度。
使用 Cohere 提供的嵌入 API,除了常规的 Float 型嵌入外,还可使用二进制嵌入。在验证中,我们使用 Cohere 的嵌入模型生成以下 3 种向量并注册到 Elasticsearch 中进行比较。
- 采用 Elasticsearch 默认设置(8 比特量化)的 float 向量
- 在 Elasticsearch 中进行比特量化(bbq)的 float 向量
- 利用 Elasticsearch 的 bit 选项注册的二进制向量
索引大小 / 正确率
以下展示了启用各选项并导入 Elasticsearch 后,索引的大小以及对数据集中预先定义的正确答案的匹配率。本次使用的数据集中,404 个检索查询均各自定义了 1 个正确文档。正确率指标采用精确率(precision)和归一化折损累积增益(nDCG)两项。
- precision@1:应匹配的正确文档排在第 1 位的比例
- nDCG@10:衡量前 10 位结果中应匹配的正确文档排名情况的指标,正确文档排名越靠前,得分越高。
| 类型 | 索引大小 | 正确率 (precision@1) | nDCG@10 |
|---|---|---|---|
| float 向量 | 9.1MB | 84.41% | 0.9108 |
| 量化 (bbq) | 8.7MB | 83.66% | 0.9024 |
| 二进制向量 | 2.6MB | 81.19% | 0.8889 |
可以看出,直接使用 float 型向量的精度确实更高,但其他方法在减小索引大小的同时,精度仅下降了 1%~3% 左右,并未出现显著下滑。近年来也有通过与重排序(rerank)结合来保证精度的策略,因此本文介绍的选项具有实用价值。当然,精度下降幅度会因数据集不同而存在差异,建议在使用前进行验证,但仍推荐积极尝试这些选项。
本文到此结束。感谢您读到最后。